
The Illustrated BERT Masked Language Modeling
Introduction
Masked Language Modeling is a fill-in-the-blank task, where a model uses the context words surrounding a mask token to try to predict what the masked word should be.
For an input that contains one or more mask tokens, the model will generate the most likely substitution for each.
Example:
Input: "I have watched this [MASK] and it was awesome."
Output: "I have watched this movie and it was awesome."
Masked language modeling is a great way to train a language model in a self-supervised setting (without human-annotated labels). Such a model can then be fine-tuned to accomplish various supervised NLP tasks.
You can also checkout on keras website with some modifications. masked_language_modeling
Setup
Install HuggingFace transformers via pip install transformers (version >= 3.1.0).
from dataclasses import dataclass
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
from transformers import TFAutoModelWithLMHead, AutoTokenizer
from transformers import pipeline
from pprint import pprint
Set-up Configuration
@dataclass
class Config:
MAX_LEN = 128
BATCH_SIZE = 16 # per TPU core
TOTAL_STEPS = 2000 # thats approx 4 epochs
EVALUATE_EVERY = 200
LR = 1e-5
PRETRAINED_MODEL = "bert-base-uncased" # huggingface bert model
flags = Config()
AUTO = tf.data.experimental.AUTOTUNE
Set-up TPU Runtime
def connect_to_TPU():
"""Detect hardware, return appropriate distribution strategy"""
try:
# TPU detection. No parameters necessary if TPU_NAME environment variable is
# set: this is always the case on Kaggle.
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
print("Running on TPU ", tpu.master())
except ValueError:
tpu = None
if tpu:
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.experimental.TPUStrategy(tpu)
else:
# Default distribution strategy in Tensorflow. Works on CPU and single GPU.
strategy = tf.distribute.get_strategy()
global_batch_size = flags.BATCH_SIZE * strategy.num_replicas_in_sync
return tpu, strategy, global_batch_size
tpu, strategy, global_batch_size = connect_to_TPU()
print("REPLICAS: ", strategy.num_replicas_in_sync)
Load Data
wget https://raw.githubusercontent.com/SrinidhiRaghavan/AI-Sentiment-Analysis-on-IMDB-Dataset/master/imdb_tr.csv
data = pd.read_csv("imdb_tr.csv", encoding="ISO-8859-1")
Prepare Masked Language Dataset

def regular_encode(texts, tokenizer, maxlen=512):
enc_di = tokenizer.batch_encode_plus(
texts,
return_attention_mask=False,
return_token_type_ids=False,
pad_to_max_length=True,
max_length=maxlen,
truncation=True,
)
return np.array(enc_di["input_ids"])
tokenizer = AutoTokenizer.from_pretrained(flags.PRETRAINED_MODEL)
X_data = regular_encode(data.text.values, tokenizer, maxlen=flags.MAX_LEN)
def prepare_mlm_input_and_labels(X):
# 15% BERT masking
inp_mask = np.random.rand(*X.shape) < 0.15
# do not mask special tokens
inp_mask[X <= 2] = False
# set targets to -1 by default, it means ignore
labels = -1 * np.ones(X.shape, dtype=int)
# set labels for masked tokens
labels[inp_mask] = X[inp_mask]
# prepare input
X_mlm = np.copy(X)
# set input to [MASK] which is the last token for the 90% of tokens
# this means leaving 10% unchanged
inp_mask_2mask = inp_mask & (np.random.rand(*X.shape) < 0.90)
X_mlm[
inp_mask_2mask
] = tokenizer.mask_token_id # mask token is the last in the dict
# set 10% to a random token
inp_mask_2random = inp_mask_2mask & (np.random.rand(*X.shape) < 1 / 9)
X_mlm[inp_mask_2random] = np.random.randint(
3, tokenizer.mask_token_id, inp_mask_2random.sum()
)
return X_mlm, labels
# use validation and test data for mlm
X_train_mlm = np.vstack(X_data)
# masks and labels
X_train_mlm, y_train_mlm = prepare_mlm_input_and_labels(X_train_mlm)
Create MaskedLanguageModel using huggingface transformers
def masked_sparse_categorical_crossentropy(y_true, y_pred):
y_true_masked = tf.boolean_mask(y_true, tf.not_equal(y_true, -1))
y_pred_masked = tf.boolean_mask(y_pred, tf.not_equal(y_true, -1))
loss = tf.keras.losses.sparse_categorical_crossentropy(
y_true_masked, y_pred_masked, from_logits=True
)
return loss
class MaskedLanguageModel(tf.keras.Model):
def train_step(self, inputs):
features, labels = inputs
with tf.GradientTape() as tape:
predictions = self(features, training=True)[0]
loss = masked_sparse_categorical_crossentropy(labels, predictions)
# Compute gradients
trainable_vars = self.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
# Update weights
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
# Compute our own metrics
loss_tracker.update_state(loss)
# Return a dict mapping metric names to current value
return {"loss": loss_tracker.result()}
@property
def metrics(self):
# We list our `Metric` objects here so that `reset_states()` can be
# called automatically at the start of each epoch
# or at the start of `evaluate()`.
# If you don't implement this property, you have to call
# `reset_states()` yourself at the time of your choosing.
return [loss_tracker]
with strategy.scope():
loss_tracker = tf.keras.metrics.Mean(name="loss")
input_layer = tf.keras.layers.Input((flags.MAX_LEN,), dtype=tf.int32)
bert_model = TFAutoModelWithLMHead.from_pretrained(flags.PRETRAINED_MODEL)
output_layer = bert_model(input_layer)
mlm_model = MaskedLanguageModel(input_layer, output_layer)
optimizer = tf.keras.optimizers.Adam(learning_rate=flags.LR)
mlm_model.compile(optimizer=optimizer)
mlm_model.summary()
Train and Save
mlm_model.fit(X_train_mlm, y_train_mlm, epochs=3, batch_size=global_batch_size)
# Save trained model using transfomers .save_pretrained()
bert_model.save_pretrained("imdb_bert_uncased")
Load and Test
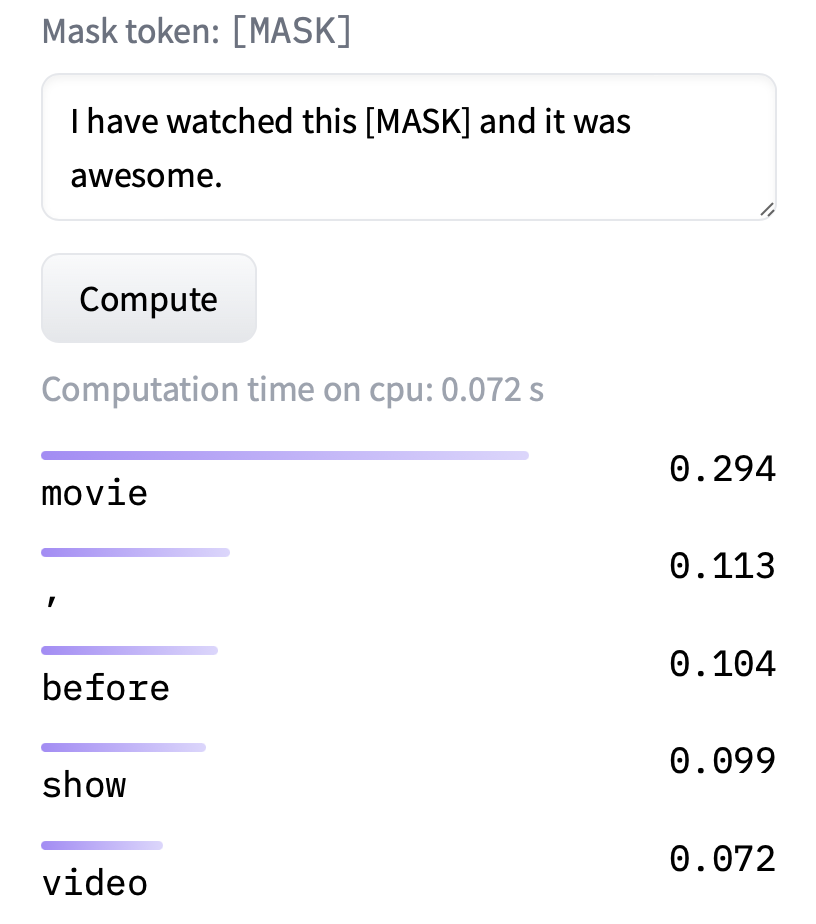
imdb_bert_model = TFAutoModelWithLMHead.from_pretrained("imdb_bert_uncased")
nlp = pipeline("fill-mask", model=imdb_bert_model, tokenizer=tokenizer, framework="tf")
pprint(nlp(f"I have watched this {nlp.tokenizer.mask_token} and it was awesome"))
Comments