
The Illustrated Dense Passage retriever
Introduction
Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional sparse vector space models, such as TF-IDF or BM25, are the defacto method. We can implement using dense representations, where embeddings are learned from a small number of questions and passages by a simple dual-encoder framework.
Original Paper link
Setup
Install transformers, faiss-cpu via pip install -q transformers faiss-cpu`.
import os
import json
import faiss
import random
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tqdm import tqdm_notebook
from dataclasses import dataclass
from tensorflow.keras import layers
from transformers import AutoTokenizer
from transformers import AutoTokenizer, TFAutoModel
Download Dataset
First we need to download train and test dataset from public data source.
wget https://dl.fbaipublicfiles.com/dpr/data/retriever/biencoder-nq-adv-hn-train.json.gz
gunzip biencoder-nq-adv-hn-train.json.gz
wget https://dl.fbaipublicfiles.com/dpr/data/retriever/biencoder-nq-dev.json.gz
gunzip biencoder-nq-dev.json.gz
Data & Model Configuration Setup
Let’s configure data and model requirements. Given we have positive passages and hard negative passages for each query. So we need to select no of positives and hard negatives need to build good representation.
For Model requirements, we need to specify things like seq_len for passage and query, pre-trained base models, learning rate, epochs, etc.
# Configure dataset
@dataclass
class DataConfig:
num_positives = 1 # No. of positive
num_hard_negatives = 1 # No of hard negatives
data_config = DataConfig()
# Configure models
@dataclass
class ModelConfig:
passage_max_seq_len = 156
query_max_seq_len = 64
batch_size_per_replica = 128
epochs = 40
learning_rate = 2e-5
num_warmup_steps = 1234
dropout = 0.1
model_name = "google/bert_uncased_L-4_H-512_A-8"
model_config = ModelConfig()
Load and Preprocess Dataset
Now, load training data and return dict which has a query and set of passages (positive n hard negatives). For the simplicity of target labels, in the passage list, place the first positive passage followed by hard negative passages.

Then, tokenize and encode passages and queries. After encoding passage-queries dict keys shape will be like, for query: (no_of_sample, query_seq_len) and for passage: (no_of_sample, num_of_passages, seq_len)
def read_dpr_json(
file,
max_samples=None,
num_hard_negatives=1,
num_positives=1,
shuffle_negatives=True,
shuffle_positives=False,
):
"""Read Json file and reture list of dicts"""
dicts = json.load(open(file, encoding="utf-8"))
# Query key options
query_json_keys = ["question", "questions", "query"]
# Positive key options
positive_context_json_keys = [
"positive_contexts",
"positive_ctxs",
"positive_context",
"positive_ctx",
]
# Hard Negative key options
hard_negative_json_keys = [
"hard_negative_contexts",
"hard_negative_ctxs",
"hard_negative_context",
"hard_negative_ctx",
]
standard_dicts = []
for i in tqdm_notebook(range(len(dicts))):
dict = dicts[i]
sample = {}
positive_passages = []
negative_passages = []
for key, val in dict.items():
if key in query_json_keys:
sample["query"] = val
elif key in positive_context_json_keys:
if shuffle_positives:
random.shuffle(val)
for passage in val[:num_positives]:
positive_passages.append(
{
"title": passage["title"],
"text": passage["text"],
"label": "positive",
}
)
elif key in hard_negative_json_keys:
if shuffle_negatives:
random.shuffle(val)
for passage in val[:num_hard_negatives]:
negative_passages.append(
{
"title": passage["title"],
"text": passage["text"],
"label": "hard_negative",
}
)
# Place Positive passage first and then negative passages
# This will be used to make in-batch labels for loss calculation.
sample["passages"] = positive_passages + negative_passages
if len(sample["passages"]) == num_positives + num_hard_negatives:
standard_dicts.append(sample)
if max_samples:
if len(standard_dicts) == max_samples:
break
return standard_dicts
# Read training json file
dicts = read_dpr_json(
"biencoder-nq-adv-hn-train.json", max_samples=6400, num_hard_negatives=1
)
def encode_query_passage(tokenizer, dicts, model_config, data_config):
"""Encode Text i.e. queries and passages into token_ids"""
passage_input_ids = []
passage_token_type_ids = []
passage_attention_mask = []
queries = []
for i in tqdm_notebook(range(len(dicts))):
di = dicts[i]
di_query = di["query"]
di_passages = di["passages"]
di_positives = [
(pi["title"], pi["text"]) for pi in di_passages if pi["label"] == "positive"
]
di_negatives = [
(ni["title"], ni["text"])
for ni in di_passages
if ni["label"] == "hard_negative"
]
if data_config.num_positives == len(
di_positives
) and data_config.num_hard_negatives == len(di_negatives):
queries.append(di_query)
i_passages = di_positives + di_negatives
i_passage_inputs = tokenizer.batch_encode_plus(
i_passages,
max_length=model_config.passage_max_seq_len,
add_special_tokens=True,
truncation=True,
truncation_strategy="longest_first",
padding="max_length",
return_token_type_ids=True,
)
passage_input_ids.append(np.array(i_passage_inputs["input_ids"]))
passage_token_type_ids.append(np.array(i_passage_inputs["token_type_ids"]))
passage_attention_mask.append(np.array(i_passage_inputs["attention_mask"]))
query_inputs = tokenizer.batch_encode_plus(
queries,
max_length=model_config.query_max_seq_len,
add_special_tokens=True,
truncation=True,
truncation_strategy="longest_first",
padding="max_length",
return_token_type_ids=True,
return_tensors="np",
)
return {
"query_input_ids": query_inputs["input_ids"],
"query_token_type_ids": query_inputs["token_type_ids"],
"query_attention_mask": query_inputs["attention_mask"],
"passage_input_ids": np.array(passage_input_ids),
"passage_token_type_ids": np.array(passage_token_type_ids),
"passage_attention_mask": np.array(passage_attention_mask),
}
# Load Pretrained tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_config.model_name)
# Encoder queries and passages
X = encode_query_passage(tokenizer, dicts, model_config, data_config)
Model Preparation
Now prepare Bi-Encoder model using pre-trained base models i.e. bert-base-uncased. We can select different models for passage and query models, but here we are using the same model base for both passage n query models.
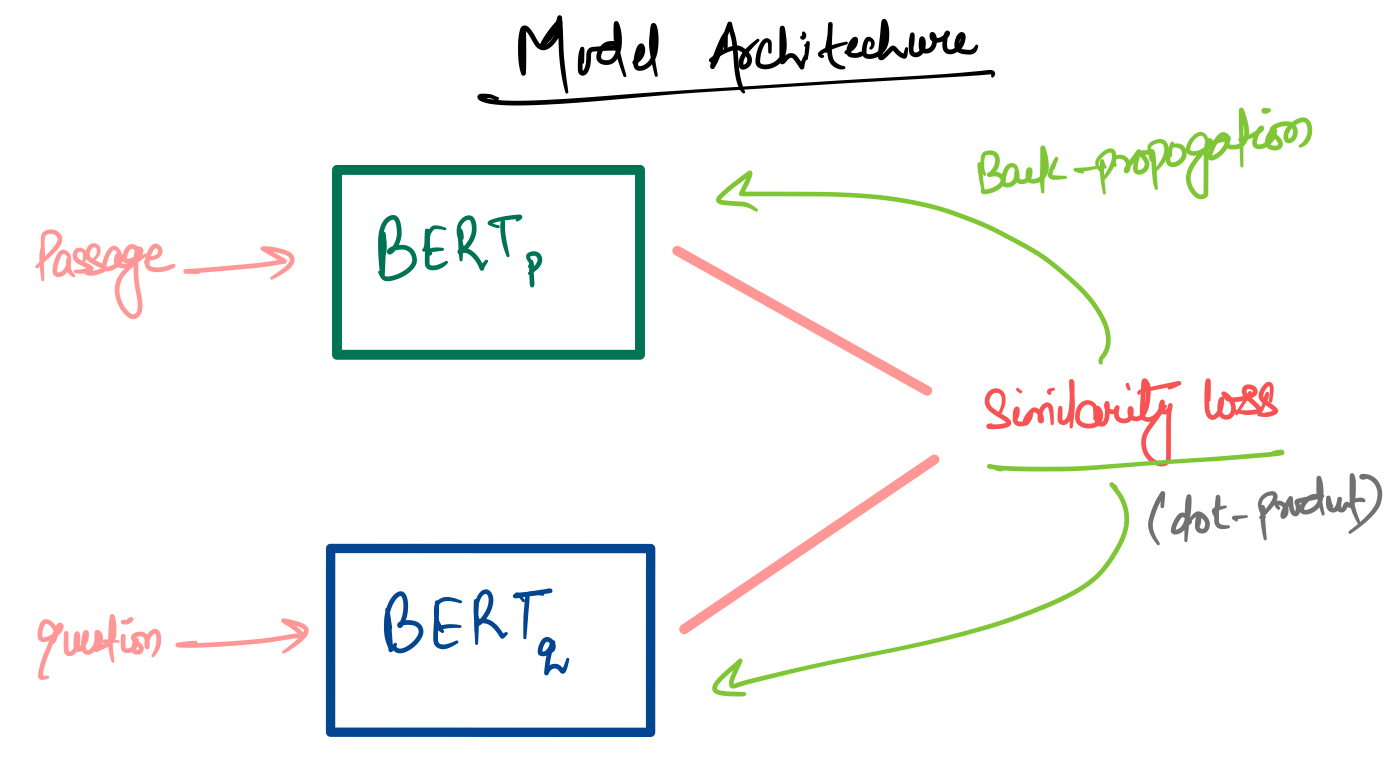
class QueryModel(tf.keras.Model):
"""Query Model"""
def __init__(self, model_config, **kwargs):
super().__init__(**kwargs)
# Load Pretrained models
self.query_encoder = TFAutoModel.from_pretrained(model_config.model_name)
# Add dropout layer
self.dropout = layers.Dropout(model_config.dropout)
def call(self, inputs, training=False, **kwargs):
pooled_output = self.query_encoder(inputs, training=training, **kwargs)[1]
pooled_output = self.dropout(pooled_output, training=training)
return pooled_output
class PassageModel(tf.keras.Model):
"""Passage Model"""
def __init__(self, model_config, **kwargs):
super().__init__(**kwargs)
# Load Pretrained models
self.passage_encoder = TFAutoModel.from_pretrained(model_config.model_name)
# Add dropout layer
self.dropout = layers.Dropout(model_config.dropout)
def call(self, inputs, training=False, **kwargs):
pooled_output = self.passage_encoder(inputs, training=training, **kwargs)[1]
pooled_output = self.dropout(pooled_output, training=training)
return pooled_output
def cross_replica_concat(values):
"""Get concat values from all replica"""
context = tf.distribute.get_replica_context()
gathered = context.all_gather(values, axis=0)
return tf.roll(
gathered,
-context.replica_id_in_sync_group * values.shape[0],
axis=0,
)
class BiEncoderModel(tf.keras.Model):
"""Bi-Encoder Query & Passage Model"""
def __init__(
self,
query_encoder,
passage_encoder,
num_passages_per_question,
model_config,
*args,
**kwargs
):
super().__init__(*args, **kwargs)
# Query encoder model
self.query_encoder = query_encoder
# Passage encoder model
self.passage_encoder = passage_encoder
# No. positives plus No. of hard negatives
self.num_passages_per_question = num_passages_per_question
# Model configuration
self.model_config = model_config
# Loss tracker
self.loss_tracker = keras.metrics.Mean(name="loss")
# Define loss
self.loss_fn = keras.losses.SparseCategoricalCrossentropy(
reduction=keras.losses.Reduction.NONE, from_logits=True
)
def calculate_loss(self, logits):
"""Function to calculate in batch loss"""
# Get no of queries from global batch size
num_queries = tf.shape(logits)[0]
# Get no of passages from global batch size
num_candidates = tf.shape(logits)[1]
# Make In-Batch Labels:
# Given single quetion positives are placed first followed by negatives.
labels = tf.convert_to_tensor(
[
i
for i in range(
0,
(GLOBAL_BATCH_SIZE * self.num_passages_per_question),
self.num_passages_per_question,
)
]
)
loss = self.loss_fn(labels, logits)
scale_loss = tf.reduce_sum(loss) * (1.0 / GLOBAL_BATCH_SIZE)
return scale_loss
def passage_forward(self, X):
# Reshape input (BS, num_passages_per_question, seq_len) -> (BS*num_passages_per_question, seq_len)
input_shape = (
self.model_config.batch_size_per_replica * self.num_passages_per_question,
self.model_config.passage_max_seq_len,
)
input_ids = tf.reshape(X["passage_input_ids"], input_shape)
attention_mask = tf.reshape(X["passage_attention_mask"], input_shape)
token_type_ids = tf.reshape(X["passage_token_type_ids"], input_shape)
# Call passage encoder model
outputs = self.passage_encoder(
[input_ids, attention_mask, token_type_ids], training=True
)
return outputs
def query_forward(self, X):
# Reshape input (BS, seq_len) -> (BS, seq_len)
input_shape = (
self.model_config.batch_size_per_replica,
self.model_config.query_max_seq_len,
)
input_ids = tf.reshape(X["query_input_ids"], input_shape)
attention_mask = tf.reshape(X["query_attention_mask"], input_shape)
token_type_ids = tf.reshape(X["query_token_type_ids"], input_shape)
outputs = self.query_encoder(
[input_ids, attention_mask, token_type_ids], training=True
)
return outputs
def train_step(self, X):
with tf.GradientTape() as tape:
# Call encoder models
passage_embeddings = self.passage_forward(X)
query_embeddings = self.query_forward(X)
# Get all replica concat values for In-Batch loss calculation
global_passage_embeddings = cross_replica_concat(passage_embeddings, 32)
global_query_embeddings = cross_replica_concat(query_embeddings, 16)
# Dot product similarity
similarity_scores = tf.linalg.matmul(
global_query_embeddings, global_passage_embeddings, transpose_b=True
)
loss = self.calculate_loss(similarity_scores)
loss = loss / strategy.num_replicas_in_sync
# Backward pass
gradients = tape.gradient(loss, self.trainable_variables)
self.optimizer.apply_gradients(zip(gradients, self.trainable_variables))
# Monitor loss
self.loss_tracker.update_state(loss)
return {"loss": self.loss_tracker.result()}
@property
def metrics(self):
return [self.loss_tracker]
Model Building and Training
Model training will be the interesting part of the whole DPR model because in this bi-encoder model training we use the In-Batch softmax loss function. What is In-Batch softmax loss?
In general, given distributed env training, each pod or node has a model copy with them. The global batch size data equally split into no of pods or nodes and each pod or node call forward pass and calculates loss separately and after that, it just aggregates each loss by some reduction methods (i.e. mean or sum), and that will be the final loss of one global-batch, this goes to each copy of models on the pod or node and the gradient update happens.
But in the In-Batch Loss method, loss calculated by concatenation values of each pod or node final output logits. We can see this in the below image.
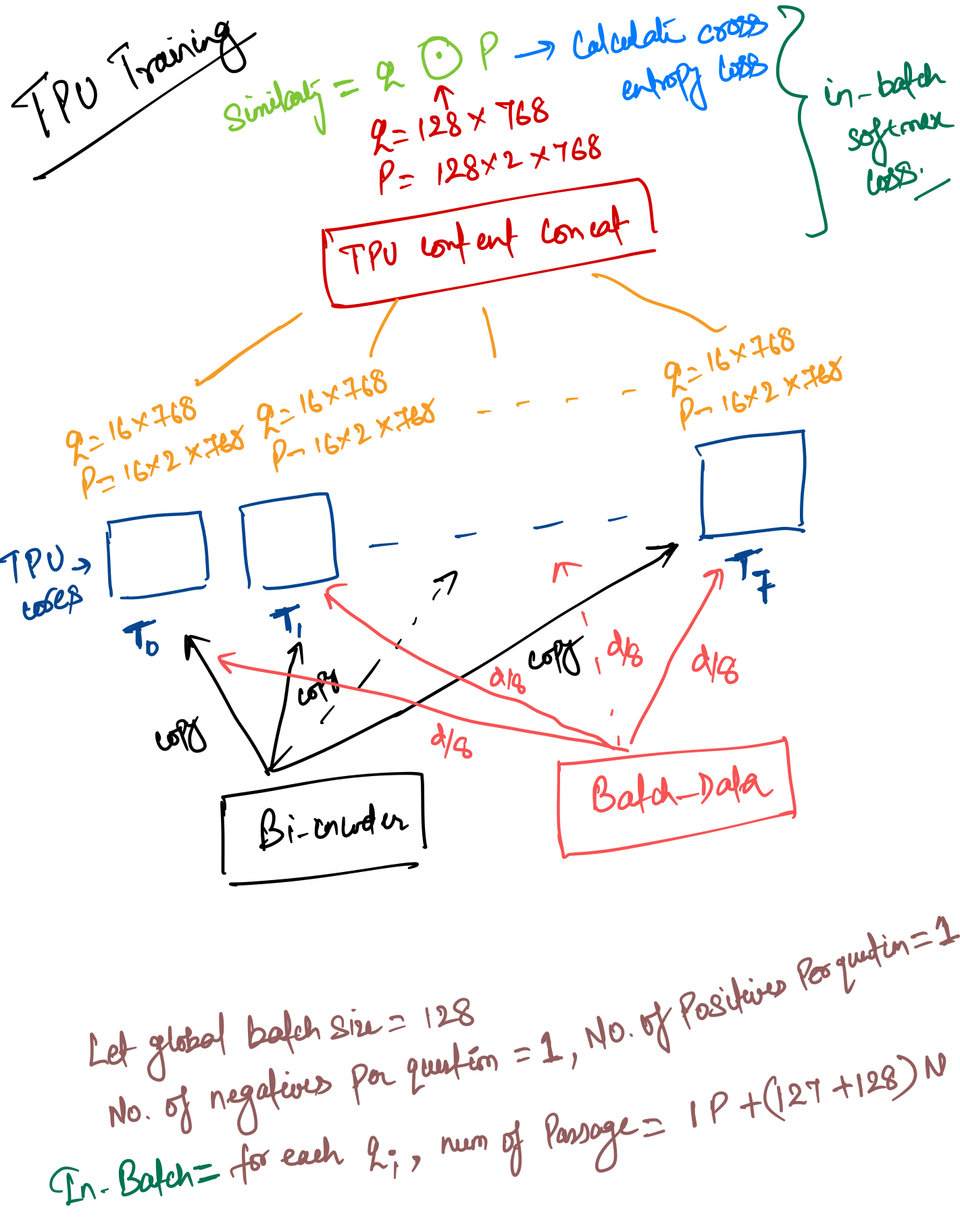
BATCH_SIZE_PER_REPLICA = model_config.batch_size_per_replica
GLOBAL_BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
N_EPOCHS = model_config.epochs
one_epoch_steps = int(len(dicts) / GLOBAL_BATCH_SIZE)
num_train_steps = one_epoch_steps * N_EPOCHS
num_warmup_steps = num_train_steps // 10
# Define model under strategy scope
with strategy.scope():
query_encoder = QueryModel(model_config)
passage_encoder = PassageModel(model_config)
bi_model = BiEncoderModel(
query_encoder,
passage_encoder,
num_passages_per_question=data_config.num_positives
+ data_config.num_hard_negatives,
model_config=model_config,
)
optimizer, lr_schedule = create_optimizer(
init_lr=model_config.learning_rate,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
)
bi_model.compile(optimizer=optimizer)
with strategy.scope():
train_ds = (
tf.data.Dataset.from_tensor_slices(X)
.shuffle(GLOBAL_BATCH_SIZE * 10)
.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
.batch(GLOBAL_BATCH_SIZE, drop_remainder=True)
)
# Train on TPU
bi_model.fit(train_ds, epochs=N_EPOCHS)
Model Evaluation
Now after training it’s time to evaluate the model on the dev dataset. We first preprocess the data into queries, passages, and answer indexes.
Queries will pass into query encoder to get query embeddings and Passages will pass into passage encoder to get passage embeddings.
Passage embedding will then stored into faiss for similarity matching.
For each query, embedding will pass into faiss.search to get the top-k index and then we will calculate the top-k acc.
# Read dev json for evaluation
eval_dicts = read_dpr_json(
"biencoder-nq-dev.json", num_hard_negatives=30, shuffle_negatives=False
)
def combine_title_context(titles, texts):
res = []
for title, ctx in zip(titles, texts):
if title is None:
title = ""
res.append(tuple((title, ctx)))
return res
def process_single_example(passages):
answer_index = -1
titles = []
texts = []
for i in range(len(passages)):
p = passages[i]
titles.append(p["title"])
texts.append(p["text"])
if p["label"] == "positive":
answer_index = i
res = combine_title_context(titles, texts)
return res, answer_index
def process_examples(dicts):
processed_passages = []
queries = []
answer_indexes = []
global_answer_index = 0
for i in range(len(dicts)):
dict_ = dicts[i]
query = dict_["query"]
queries.append(query)
passages = dict_["passages"]
res, answer_index = process_single_example(passages)
i_answer_index = global_answer_index + answer_index
processed_passages.extend(res)
answer_indexes.append(i_answer_index)
global_answer_index = global_answer_index + len(passages)
return queries, answer_indexes, processed_passages
# Process examples for evaluation
queries, answer_indexes, processed_passages = process_examples(eval_dicts)
print(len(processed_passages), len(queries))
def extracted_passage_embeddings(processed_passages, model_config):
"""Extract Passage Embeddings"""
passage_inputs = tokenizer.batch_encode_plus(
processed_passages,
add_special_tokens=True,
truncation=True,
padding="max_length",
max_length=model_config.passage_max_seq_len,
return_token_type_ids=True,
)
passage_embeddings = passage_encoder.predict(
[
np.array(passage_inputs["input_ids"]),
np.array(passage_inputs["attention_mask"]),
np.array(passage_inputs["token_type_ids"]),
],
batch_size=512,
verbose=1,
)
return passage_embeddings
passage_embeddings = extracted_passage_embeddings(processed_passages, model_config)
def extracted_query_embeddings(queries, model_config):
"""Extract Query Embeddings"""
query_inputs = tokenizer.batch_encode_plus(
queries,
add_special_tokens=True,
truncation=True,
padding="max_length",
max_length=model_config.query_max_seq_len,
return_token_type_ids=True,
)
query_embeddings = query_encoder.predict(
[
np.array(query_inputs["input_ids"]),
np.array(query_inputs["attention_mask"]),
np.array(query_inputs["token_type_ids"]),
],
batch_size=512,
verbose=1,
)
return query_embeddings
query_embeddings = extracted_query_embeddings(queries, model_config)
# Load into Faiss
faiss_index = faiss.IndexFlatL2(768)
faiss_index.add(passage_embeddings)
def get_k_accuracy(faiss_index, query_embeddings, answer_indexes, k):
prob, index = faiss_index.search(query_embeddings, k=k)
corrects = []
for i in tqdm_notebook(range(len(answer_indexes))):
i_index = index[i]
i_count = len(np.where(i_index == answer_indexes[i])[0])
if i_count > 0:
corrects.append((i, answer_indexes[i]))
return corrects
# Calculate Top-k Acc.
top10_corrects = get_k_accuracy(faiss_index, query_embeddings, answer_indexes, k=10)
top20_corrects = get_k_accuracy(faiss_index, query_embeddings, answer_indexes, k=20)
top50_corrects = get_k_accuracy(faiss_index, query_embeddings, answer_indexes, k=50)
top100_corrects = get_k_accuracy(faiss_index, query_embeddings, answer_indexes, k=100)
top1000_corrects = get_k_accuracy(faiss_index, query_embeddings, answer_indexes, k=1000)
results = pd.DataFrame(
{
"topK": [10, 20, 50, 100, 1000],
"total": [len(query_embeddings)] * 5,
"correct_total": [
len(top10_corrects),
len(top20_corrects),
len(top50_corrects),
len(top100_corrects),
len(top1000_corrects),
],
}
)
# Show results
results["accuracy"] = (results["correct_total"] / results["total"]) * 100
print(results)
References
DPR Paper: https://arxiv.org/pdf/2004.04906.pdf
Blog: https://ankur3107.github.io/blogs/dense-passage-retriever/
Cited as
@article{kumar2021dprtpu,
title = "The Illustrated Dense Passage Retreiver on TPU",
author = "Kumar, Ankur",
journal = "ankur3107.github.io",
year = "2021",
url = "https://ankur3107.github.io/blogs/dense-passage-retriever/"
}
Comments