
SQuAD 2.0: How I reached in Top 6
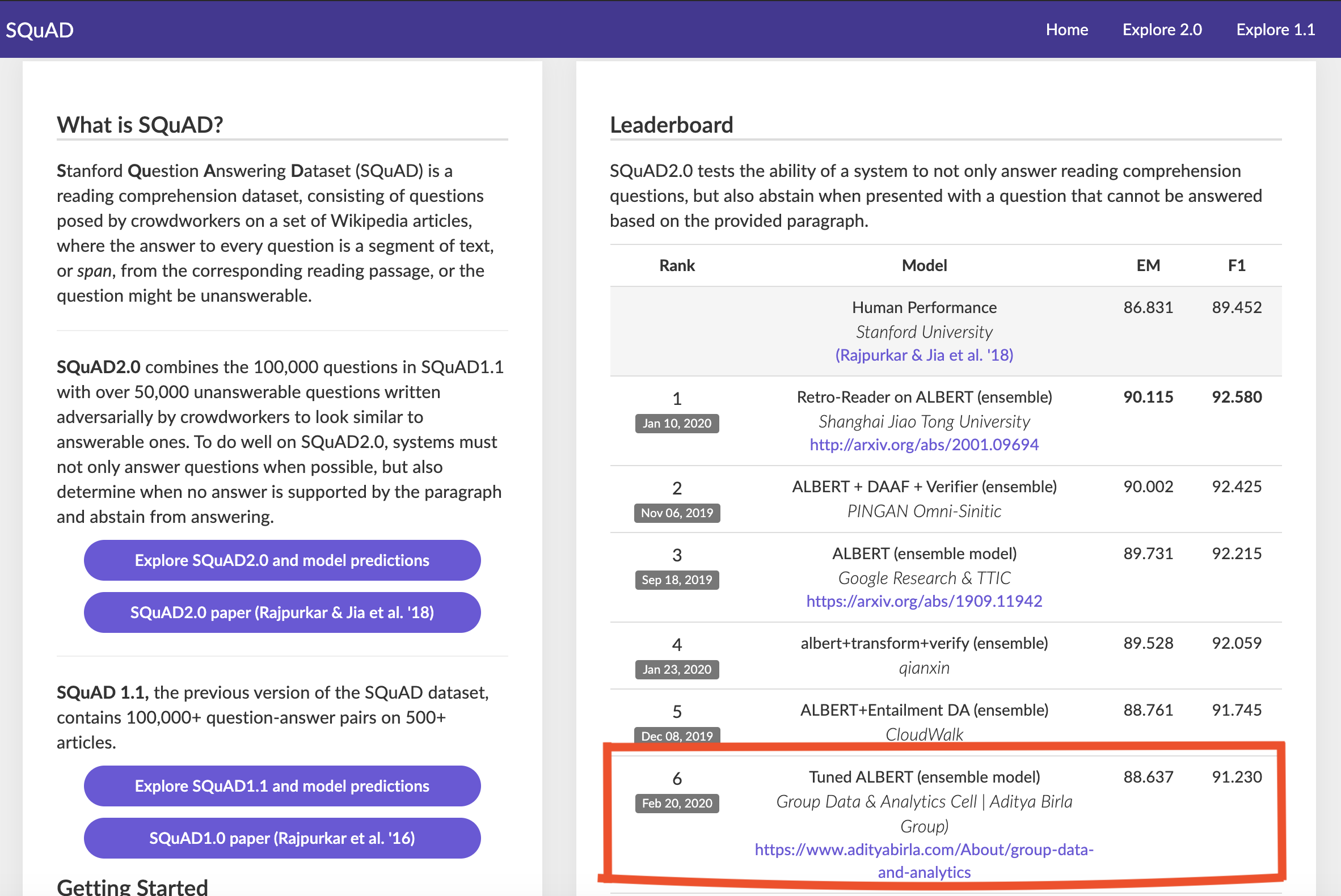
What is SQuAD
-
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
-
SQuAD2.0 combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
-
Types of examples in SQuAD 2.0
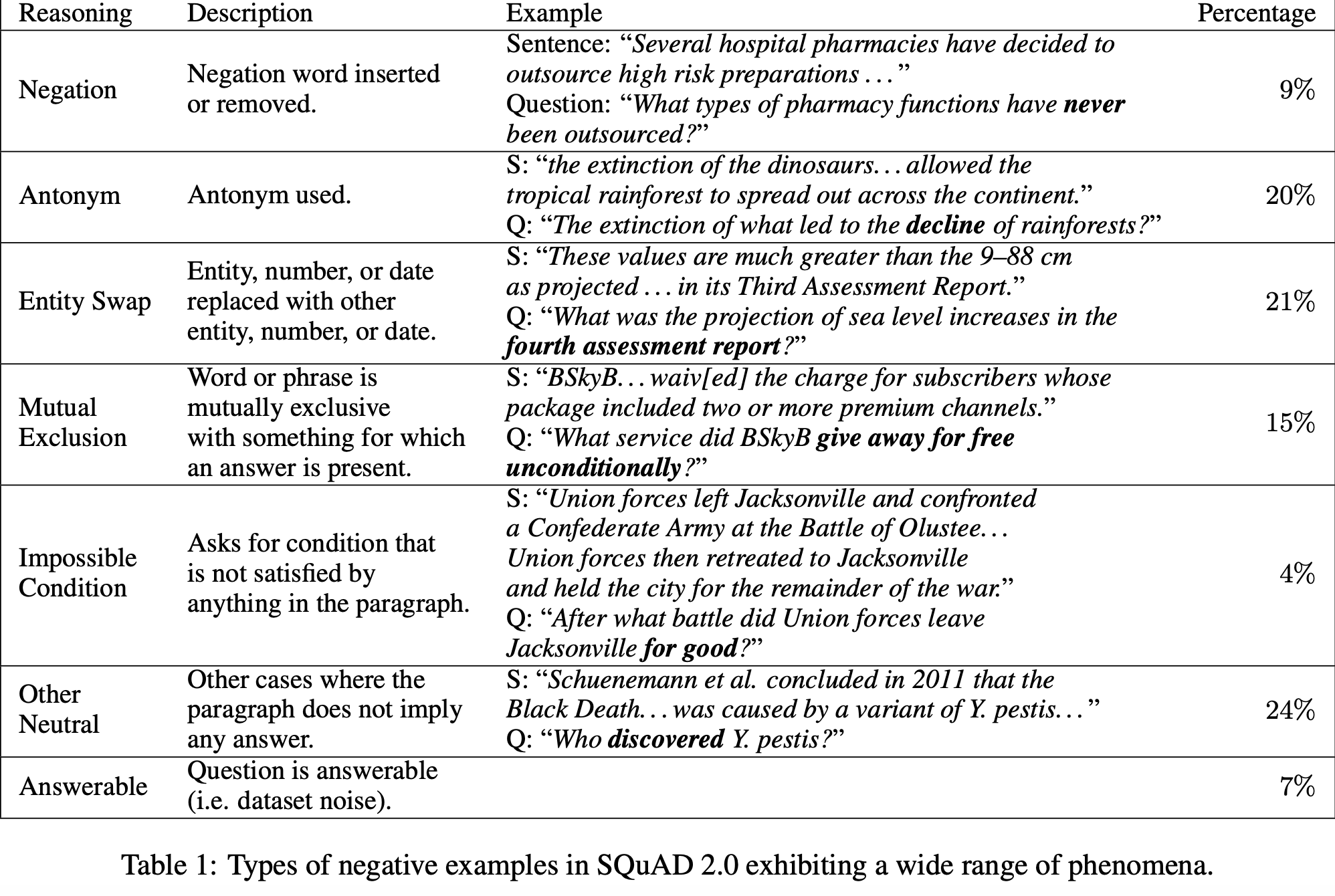
-
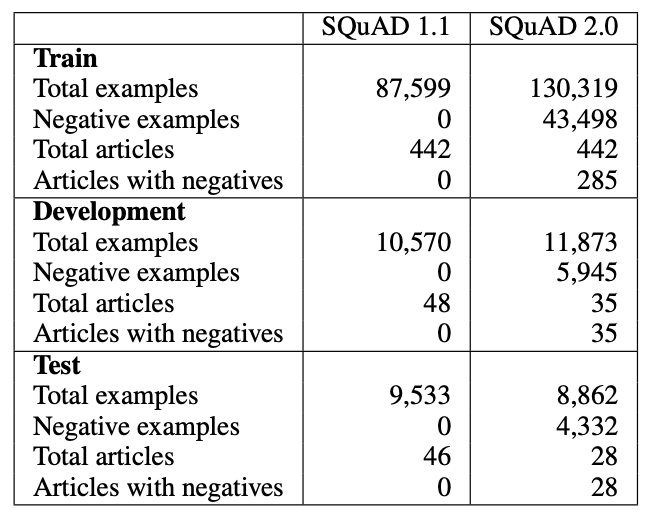
Dataset statistics of SQuAD 2.0
Strategy
Now I am going to explain step by step, how I approached SQuAD2.0:
-
Data Pre-Processing:
Data pre-processing was the most time-consuming process and it took around 6-8h of computation time. The process was as followed:
1. Text Cleaning 2. Tokenization (Sentencepiece) 3. Data-format prepration for model input 4. Serialization into TFRecords -
Tuned Albert:
Tuned Abert model Architecture built on Albert transformer network.
1. Base Network - Transformer 2. Albert Architecture (Multi Headed Self Attention) 3. QA Layer Architecture 4. Parameter Tuning - Hidden layer size, attention in QA Layers etc -
Training Strategy:
For training tuned Albert, used below strategies:
1. Learning Rate Decay based Training 2. Tuned Loss function after some epochs 3. Dataset Ratio Tuning(Answerable/ Unanswerable) -
Ensembling Strategy:
For ensembling, used bagging technique and took the mean probability of two models:
1. Model 1 - with full dataset 2. Model 2 – Model 1 + Additional Dataset of specific Class -
Computation:
For training tuned albert, it took 100h+ DGX-GPU(2 V100) computation.
For Submission
- Upload Model+Code on Codalab
- Made Docker image for my requirement
- Run Tuned Albert for Dev data using Docker image+Model+Code
- Submitted the final image link.
Special Thanks for help and support
- Naveen Xavier: https://in.linkedin.com/in/naveenxavier
- Arun Raghuraman: https://in.linkedin.com/in/arun-raghuraman-50a20b60
- Shruti Mittal: https://in.linkedin.com/in/shruti-mittal
Comments