
BERTology: How Bert Works

Overview of BERT architecture
Fundamentally, BERT is a stack of Transformer encoder layers (Vaswani et al., 2017) which consist of multiple “heads”, i.e., fully-connected neural networks augmented with a self-attention mechanism. For every input token in a sequence, each head computes key, value and query vectors, which are used to create a weighted representation. The outputs of all heads in the same layer are combined and run through a fully-connected layer. Each layer is wrapped with a skip connection and layer normalization is applied after it.
BERT embeddings
- BERT embeddings occupy a narrow cone in the vector space, and this effect increases from lower to higher layers. That is, two random words will on average have a much higher cosine similarity than expected if embeddings were directionally uniform (isotropic).
Syntactic knowledge
- BERT representations are hierarchical rather than linear
- BERT embeddings encode information about parts of speech, syntactic chunks and roles
- Syntactic structure is not directly encoded in self-attention weights, but they can be transformed to reflect it.
-
Able to learn transformation matrices that would successfully recover much of the Stanford Dependencies formalism for PennTreebank data
-
BERT takes subject-predicate agreement into account when performing the cloze task
- BERT is better able to detect the presence of NPIs (e.g. ”ever”) and the words that allow their use (e.g. ”whether”) than scope violations.
Semantic knowledge
-
BERT encodes information about entity types, relations, semantic roles, and proto-roles, since this information can be detected with probing classifiers.
-
BERT struggles with representations of numbers. Addition and number decoding tasks showed that BERT does not form good representations for floating point numbers and fails to generalize away from the training data
World knowledge
-
BERT cannot reason based on its world knowledge. Forbes et al. (2019) show that BERT can “guess” the affordances and properties of many objects, but does not have the information about their interactions (e.g. it “knows” that people can walk into houses, and that houses are big, but it cannot infer that houses are bigger than people.)
-
At the same time, Poerner et al. (2019) show that some of BERT’s success in factoid knowledge retrieval comes from learning stereotypical character combinations, e.g. it would predict that a person with an Italian-sounding name is Italian, even when it is factually incorrect.
Self-attention heads
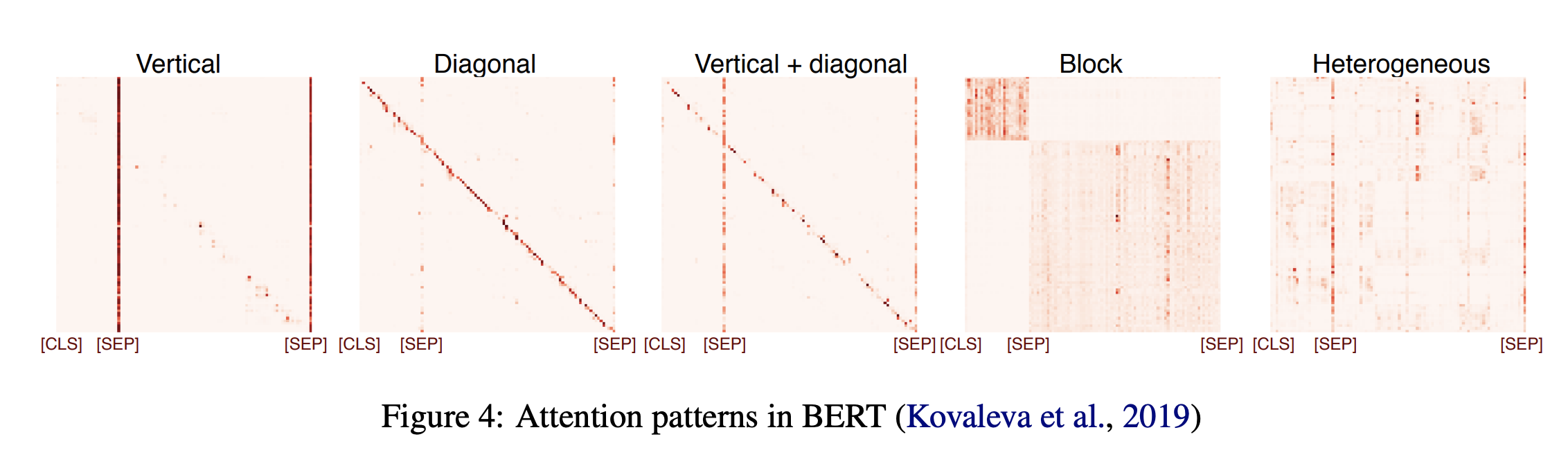
-
Most selfattention heads do not directly encode any nontrivial linguistic information, since less than half of them had the “heterogeneous” pattern
-
Some BERT heads seem to specialize in certain types of syntactic relations.
-
No single head has the complete syntactic tree information, in line with evidence of partial knowledge of syntax
-
Even when attention heads specialize in tracking semantic relations, they do not necessarily contribute to BERT’s performance on relevant tasks.
BERT layers
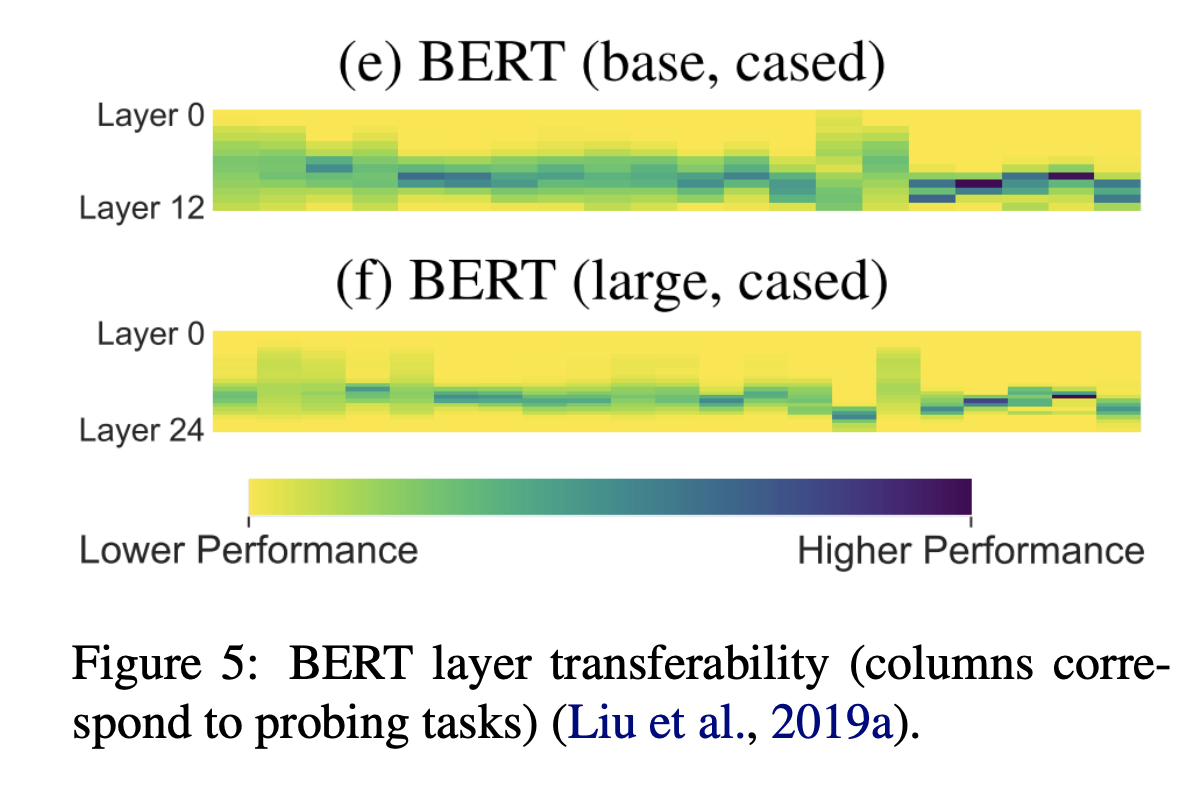
-
The lower layers have the most linear word order information
-
syntactic information is the most prominent in the middle BERT layers
**Checkout the Offical Paper ***
Comments