![]()
Question Answering with a Fine-Tuned BERT
by Ankur Singh
Part 1: How BERT is applied to Question Answering
The SQuAD v1.1 Benchmark
When someone mentions "Question Answering" as an application of BERT, what they are really referring to is applying BERT to the Stanford Question Answering Dataset (SQuAD).
The task posed by the SQuAD benchmark is a little different than you might think. Given a question, and a passage of text containing the answer, BERT needs to highlight the "span" of text corresponding to the correct answer.
The SQuAD homepage has a fantastic tool for exploring the questions and reference text for this dataset, and even shows the predictions made by top-performing models.
For example, here are some interesting examples on the topic of Super Bowl 50.
BERT Input Format
To feed a QA task into BERT, we pack both the question and the reference text into the input.
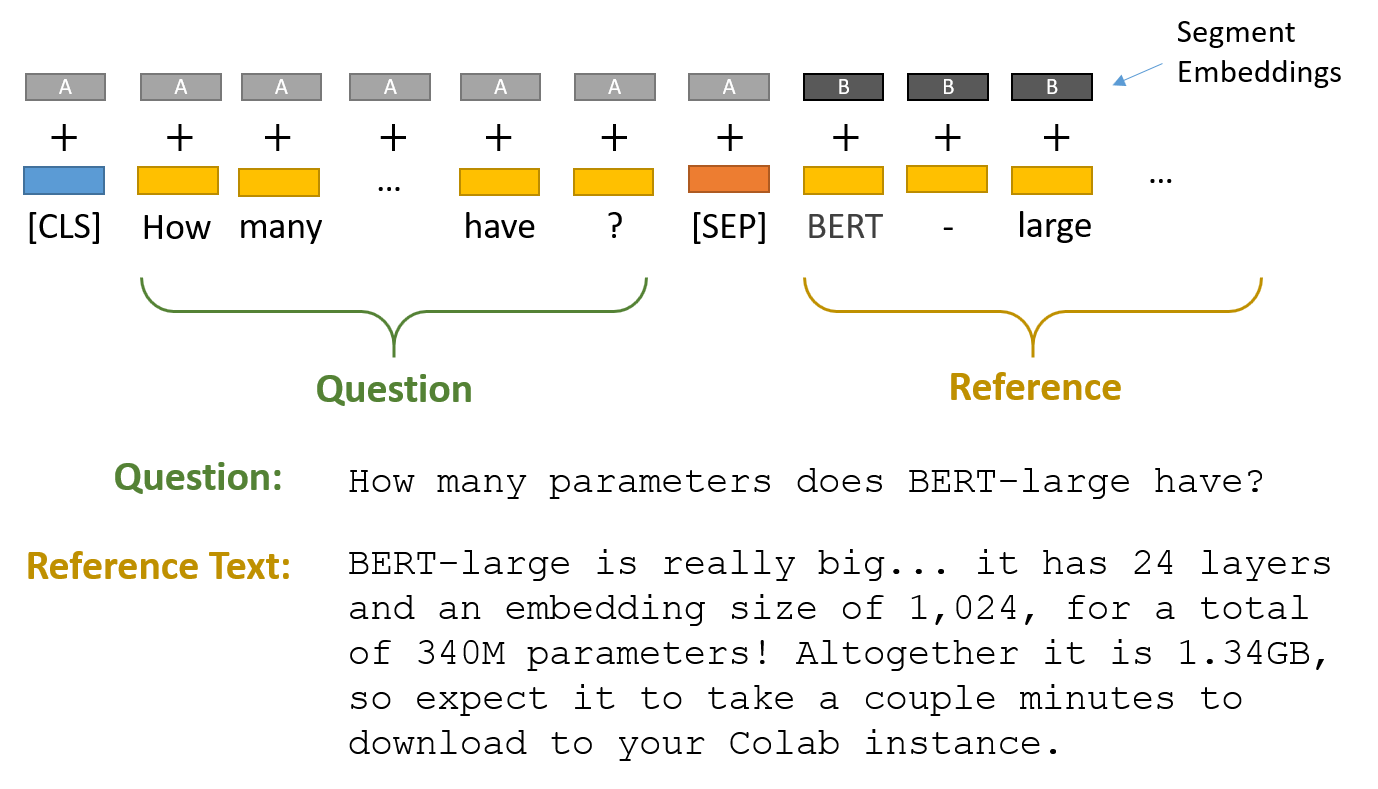
The two pieces of text are separated by the special [SEP] token.
BERT also uses "Segment Embeddings" to differentiate the question from the reference text. These are simply two embeddings (for segments "A" and "B") that BERT learned, and which it adds to the token embeddings before feeding them into the input layer.
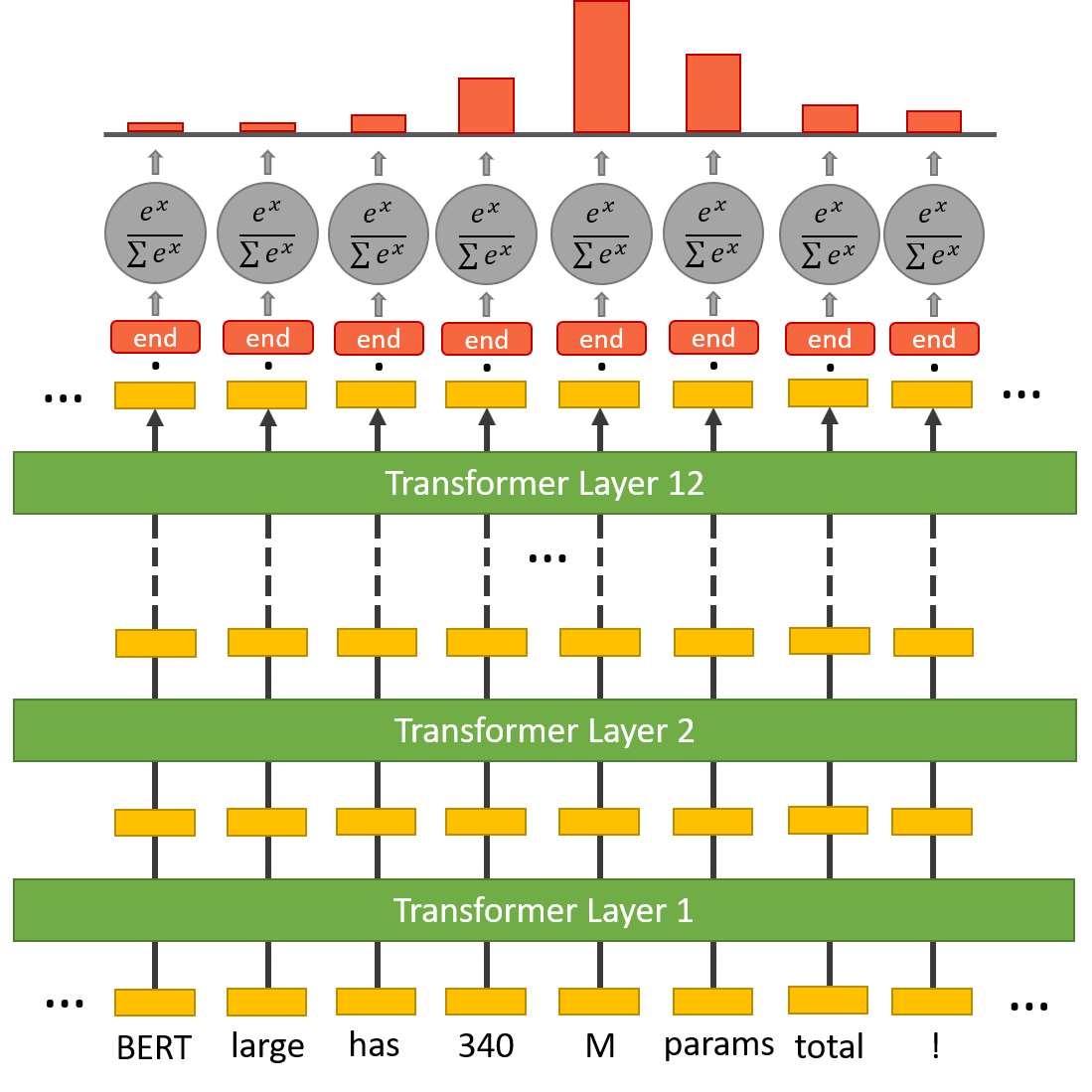
Start & End Token Classifiers
BERT needs to highlight a "span" of text containing the answer--this is represented as simply predicting which token marks the start of the answer, and which token marks the end.
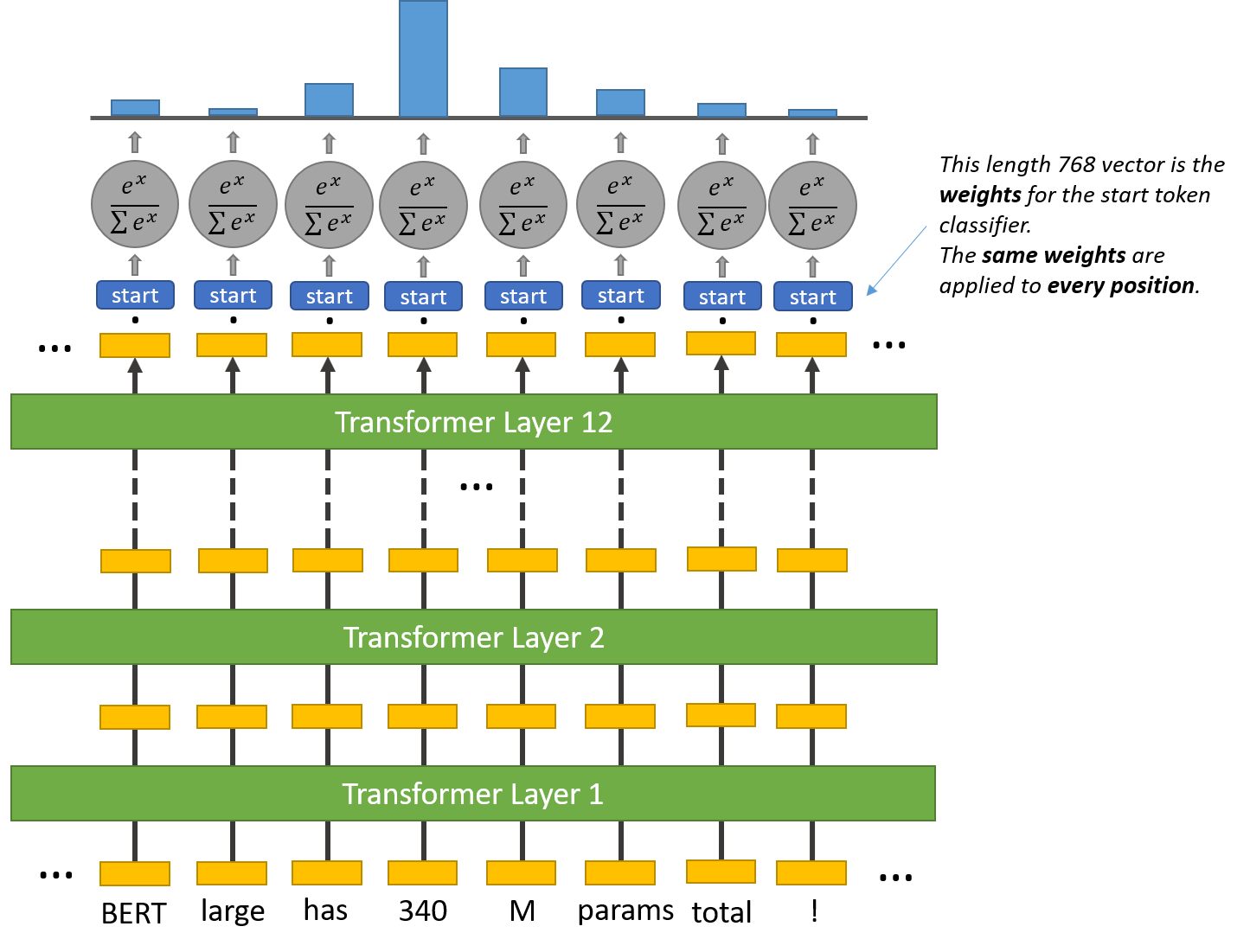
For every token in the text, we feed its final embedding into the start token classifier. The start token classifier only has a single set of weights (represented by the blue "start" rectangle in the above illustration) which it applies to every word.
After taking the dot product between the output embeddings and the 'start' weights, we apply the softmax activation to produce a probability distribution over all of the words. Whichever word has the highest probability of being the start token is the one that we pick.
We repeat this process for the end token--we have a separate weight vector this.
Part 2: Example Code
In the example code below, we'll be downloading a model that's already been fine-tuned for question answering, and try it out on our own text.
If you do want to fine-tune on your own dataset, it is possible to fine-tune BERT for question answering yourself. See run_squad.py in the transformers library. However,you may find that the below "fine-tuned-on-squad" model already does a good job, even if your text is from a different domain.
Note: The example code in this Notebook is a commented and expanded version of the short example provided in the
transformersdocumentation here.
1. Install huggingface transformers library
This example uses the transformers library by huggingface. We'll start by installing the package.
!pip install transformers
Collecting transformers
[?25l Downloading https://files.pythonhosted.org/packages/27/3c/91ed8f5c4e7ef3227b4119200fc0ed4b4fd965b1f0172021c25701087825/transformers-3.0.2-py3-none-any.whl (769kB)
[K |████████████████████████████████| 778kB 8.6MB/s
[?25hRequirement already satisfied: packaging in /usr/local/lib/python3.6/dist-packages (from transformers) (20.4)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.6/dist-packages (from transformers) (2019.12.20)
Requirement already satisfied: dataclasses; python_version < "3.7" in /usr/local/lib/python3.6/dist-packages (from transformers) (0.7)
Requirement already satisfied: requests in /usr/local/lib/python3.6/dist-packages (from transformers) (2.23.0)
Collecting sacremoses
[?25l Downloading https://files.pythonhosted.org/packages/7d/34/09d19aff26edcc8eb2a01bed8e98f13a1537005d31e95233fd48216eed10/sacremoses-0.0.43.tar.gz (883kB)
[K |████████████████████████████████| 890kB 14.4MB/s
[?25hCollecting tokenizers==0.8.1.rc1
[?25l Downloading https://files.pythonhosted.org/packages/40/d0/30d5f8d221a0ed981a186c8eb986ce1c94e3a6e87f994eae9f4aa5250217/tokenizers-0.8.1rc1-cp36-cp36m-manylinux1_x86_64.whl (3.0MB)
[K |████████████████████████████████| 3.0MB 43.4MB/s
[?25hCollecting sentencepiece!=0.1.92
[?25l Downloading https://files.pythonhosted.org/packages/d4/a4/d0a884c4300004a78cca907a6ff9a5e9fe4f090f5d95ab341c53d28cbc58/sentencepiece-0.1.91-cp36-cp36m-manylinux1_x86_64.whl (1.1MB)
[K |████████████████████████████████| 1.1MB 44.5MB/s
[?25hRequirement already satisfied: filelock in /usr/local/lib/python3.6/dist-packages (from transformers) (3.0.12)
Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.6/dist-packages (from transformers) (4.41.1)
Requirement already satisfied: numpy in /usr/local/lib/python3.6/dist-packages (from transformers) (1.18.5)
Requirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from packaging->transformers) (1.15.0)
Requirement already satisfied: pyparsing>=2.0.2 in /usr/local/lib/python3.6/dist-packages (from packaging->transformers) (2.4.7)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests->transformers) (2020.6.20)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests->transformers) (2.10)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests->transformers) (3.0.4)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests->transformers) (1.24.3)
Requirement already satisfied: click in /usr/local/lib/python3.6/dist-packages (from sacremoses->transformers) (7.1.2)
Requirement already satisfied: joblib in /usr/local/lib/python3.6/dist-packages (from sacremoses->transformers) (0.16.0)
Building wheels for collected packages: sacremoses
Building wheel for sacremoses (setup.py) ... [?25l[?25hdone
Created wheel for sacremoses: filename=sacremoses-0.0.43-cp36-none-any.whl size=893257 sha256=09966dce42bbfaa2aa5abc0f5f82653b74458d122a6fefeb7c895da49b40ce50
Stored in directory: /root/.cache/pip/wheels/29/3c/fd/7ce5c3f0666dab31a50123635e6fb5e19ceb42ce38d4e58f45
Successfully built sacremoses
Installing collected packages: sacremoses, tokenizers, sentencepiece, transformers
Successfully installed sacremoses-0.0.43 sentencepiece-0.1.91 tokenizers-0.8.1rc1 transformers-3.0.2
import torch
2. Load Fine-Tuned BERT-large
For Question Answering we use the BertForQuestionAnswering class from the transformers library.
This class supports fine-tuning, but for this example we will keep things simpler and load a BERT model that has already been fine-tuned for the SQuAD benchmark.
The transformers library has a large collection of pre-trained models which you can reference by name and load easily. The full list is in their documentation here.
For Question Answering, they have a version of BERT-large that has already been fine-tuned for the SQuAD benchmark.
BERT-large is really big... it has 24-layers and an embedding size of 1,024, for a total of 340M parameters! Altogether it is 1.34GB, so expect it to take a couple minutes to download to your Colab instance.
(Note that this download is not using your own network bandwidth--it's between the Google instance and wherever the model is stored on the web).
Note: I believe this model was trained on version 1 of SQuAD, since it's not outputting whether the question is "impossible" to answer from the text (which is part of the task in v2 of SQuAD).
from transformers import BertForQuestionAnswering
model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=443.0, style=ProgressStyle(description_…
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=1340675298.0, style=ProgressStyle(descr…
Load the tokenizer as well.
Side note: Apparently the vocabulary of this model is identicaly to the one in bert-base-uncased. You can load the tokenizer from bert-base-uncased and that works just as well.
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=231508.0, style=ProgressStyle(descripti…
3. Ask a Question
Now we're ready to feed in an example!
A QA example consists of a question and a passage of text containing the answer to that question.
Let's try an example using the text in this tutorial!
question = "How many parameters does BERT-large have?"
answer_text = "BERT-large is really big... it has 24-layers and an embedding size of 1,024, for a total of 340M parameters! Altogether it is 1.34GB, so expect it to take a couple minutes to download to your Colab instance."
We'll need to run the BERT tokenizer against both the question and the answer_text. To feed these into BERT, we actually concatenate them together and place the special [SEP] token in between.
# Apply the tokenizer to the input text, treating them as a text-pair.
input_ids = tokenizer.encode(question, answer_text)
print('The input has a total of {:} tokens.'.format(len(input_ids)))
The input has a total of 70 tokens.
Just to see exactly what the tokenizer is doing, let's print out the tokens with their IDs.
# BERT only needs the token IDs, but for the purpose of inspecting the
# tokenizer's behavior, let's also get the token strings and display them.
tokens = tokenizer.convert_ids_to_tokens(input_ids)
# For each token and its id...
for token, id in zip(tokens, input_ids):
# If this is the [SEP] token, add some space around it to make it stand out.
if id == tokenizer.sep_token_id:
print('')
# Print the token string and its ID in two columns.
print('{:<12} {:>6,}'.format(token, id))
if id == tokenizer.sep_token_id:
print('')
[CLS] 101
how 2,129
many 2,116
parameters 11,709
does 2,515
bert 14,324
- 1,011
large 2,312
have 2,031
? 1,029
[SEP] 102
bert 14,324
- 1,011
large 2,312
is 2,003
really 2,428
big 2,502
. 1,012
. 1,012
. 1,012
it 2,009
has 2,038
24 2,484
- 1,011
layers 9,014
and 1,998
an 2,019
em 7,861
##bed 8,270
##ding 4,667
size 2,946
of 1,997
1 1,015
, 1,010
02 6,185
##4 2,549
, 1,010
for 2,005
a 1,037
total 2,561
of 1,997
340 16,029
##m 2,213
parameters 11,709
! 999
altogether 10,462
it 2,009
is 2,003
1 1,015
. 1,012
34 4,090
##gb 18,259
, 1,010
so 2,061
expect 5,987
it 2,009
to 2,000
take 2,202
a 1,037
couple 3,232
minutes 2,781
to 2,000
download 8,816
to 2,000
your 2,115
cola 15,270
##b 2,497
instance 6,013
. 1,012
[SEP] 102
We've concatenated the question and answer_text together, but BERT still needs a way to distinguish them. BERT has two special "Segment" embeddings, one for segment "A" and one for segment "B". Before the word embeddings go into the BERT layers, the segment A embedding needs to be added to the question tokens, and the segment B embedding needs to be added to each of the answer_text tokens.
These additions are handled for us by the transformer library, and all we need to do is specify a '0' or '1' for each token.
Note: In the transformers library, huggingface likes to call these token_type_ids, but I'm going with segment_ids since this seems clearer, and is consistent with the BERT paper.
# Search the input_ids for the first instance of the `[SEP]` token.
sep_index = input_ids.index(tokenizer.sep_token_id)
# The number of segment A tokens includes the [SEP] token istelf.
num_seg_a = sep_index + 1
# The remainder are segment B.
num_seg_b = len(input_ids) - num_seg_a
# Construct the list of 0s and 1s.
segment_ids = [0]*num_seg_a + [1]*num_seg_b
# There should be a segment_id for every input token.
assert len(segment_ids) == len(input_ids)
Side Note: Where's the padding?
The original example code does not perform any padding. I suspect that this is because we are only feeding in a single example. If we instead fed in a batch of examples, then we would need to pad or truncate all of the samples in the batch to a single length, and supply an attention mask to tell BERT to ignore the padding tokens.
We're ready to feed our example into the model!
# Run our example through the model.
start_scores, end_scores = model(torch.tensor([input_ids]), # The tokens representing our input text.
token_type_ids=torch.tensor([segment_ids])) # The segment IDs to differentiate question from answer_text
Now we can highlight the answer just by looking at the most probable start and end words.
# Find the tokens with the highest `start` and `end` scores.
answer_start = torch.argmax(start_scores)
answer_end = torch.argmax(end_scores)
# Combine the tokens in the answer and print it out.
answer = ' '.join(tokens[answer_start:answer_end+1])
print('Answer: "' + answer + '"')
Answer: "340 ##m"
It got it right! Awesome :)
Side Note: It's a little naive to pick the highest scores for start and end--what if it predicts an end word that's before the start word?! The correct implementation is to pick the highest total score for which end >= start.
With a little more effort, we can reconstruct any words that got broken down into subwords.
# Start with the first token.
answer = tokens[answer_start]
# Select the remaining answer tokens and join them with whitespace.
for i in range(answer_start + 1, answer_end + 1):
# If it's a subword token, then recombine it with the previous token.
if tokens[i][0:2] == '##':
answer += tokens[i][2:]
# Otherwise, add a space then the token.
else:
answer += ' ' + tokens[i]
print('Answer: "' + answer + '"')
Answer: "340m"
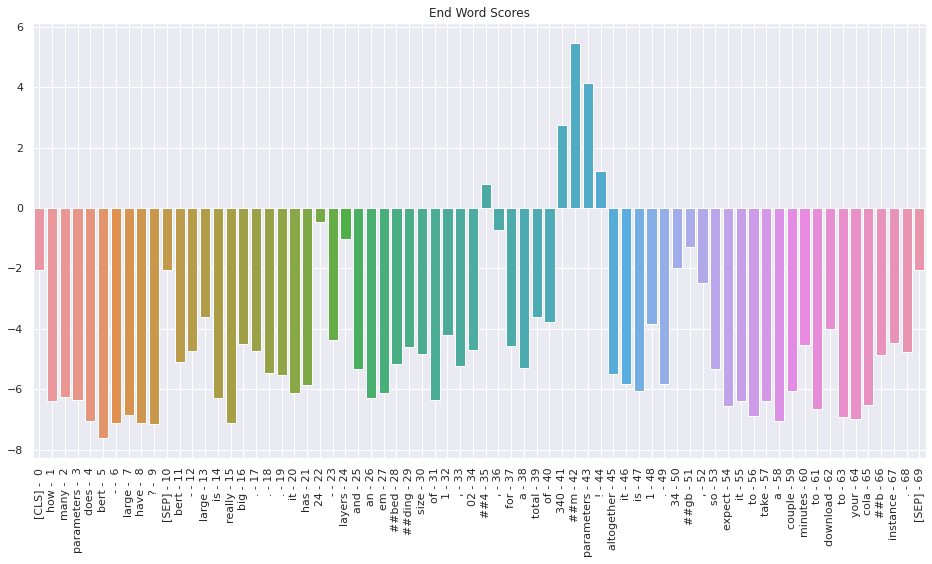
4. Visualizing Scores
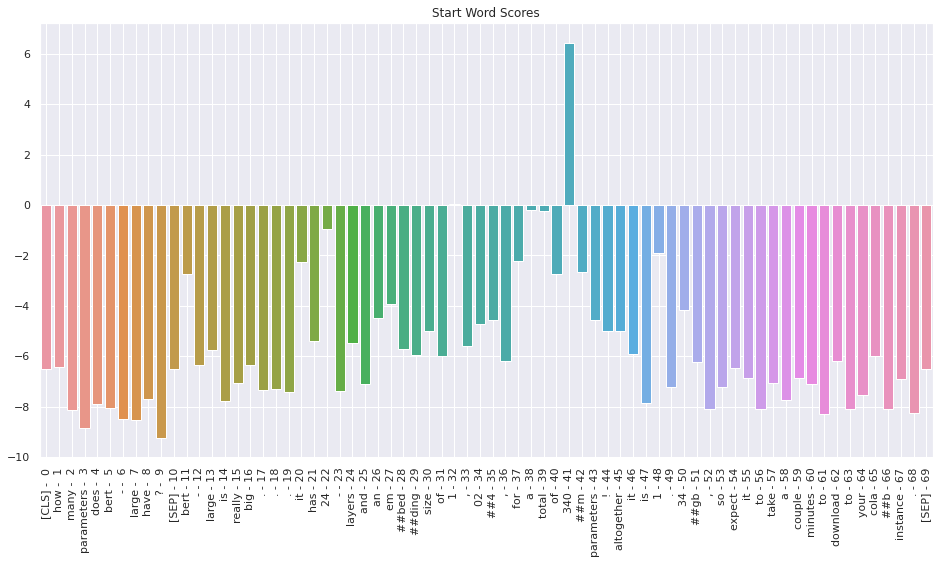
I was curious to see what the scores were for all of the words. The following cells generate bar plots showing the start and end scores for every word in the input.
import matplotlib.pyplot as plt
import seaborn as sns
# Use plot styling from seaborn.
sns.set(style='darkgrid')
# Increase the plot size and font size.
#sns.set(font_scale=1.5)
plt.rcParams["figure.figsize"] = (16,8)
Retrieve all of the start and end scores, and use all of the tokens as x-axis labels.
# Pull the scores out of PyTorch Tensors and convert them to 1D numpy arrays.
s_scores = start_scores.detach().numpy().flatten()
e_scores = end_scores.detach().numpy().flatten()
# We'll use the tokens as the x-axis labels. In order to do that, they all need
# to be unique, so we'll add the token index to the end of each one.
token_labels = []
for (i, token) in enumerate(tokens):
token_labels.append('{:} - {:>2}'.format(token, i))
Create a bar plot showing the score for every input word being the "start" word.
# Create a barplot showing the start word score for all of the tokens.
ax = sns.barplot(x=token_labels, y=s_scores, ci=None)
# Turn the xlabels vertical.
ax.set_xticklabels(ax.get_xticklabels(), rotation=90, ha="center")
# Turn on the vertical grid to help align words to scores.
ax.grid(True)
plt.title('Start Word Scores')
plt.show()
Create a second bar plot showing the score for every input word being the "end" word.
# Create a barplot showing the end word score for all of the tokens.
ax = sns.barplot(x=token_labels, y=e_scores, ci=None)
# Turn the xlabels vertical.
ax.set_xticklabels(ax.get_xticklabels(), rotation=90, ha="center")
# Turn on the vertical grid to help align words to scores.
ax.grid(True)
plt.title('End Word Scores')
plt.show()
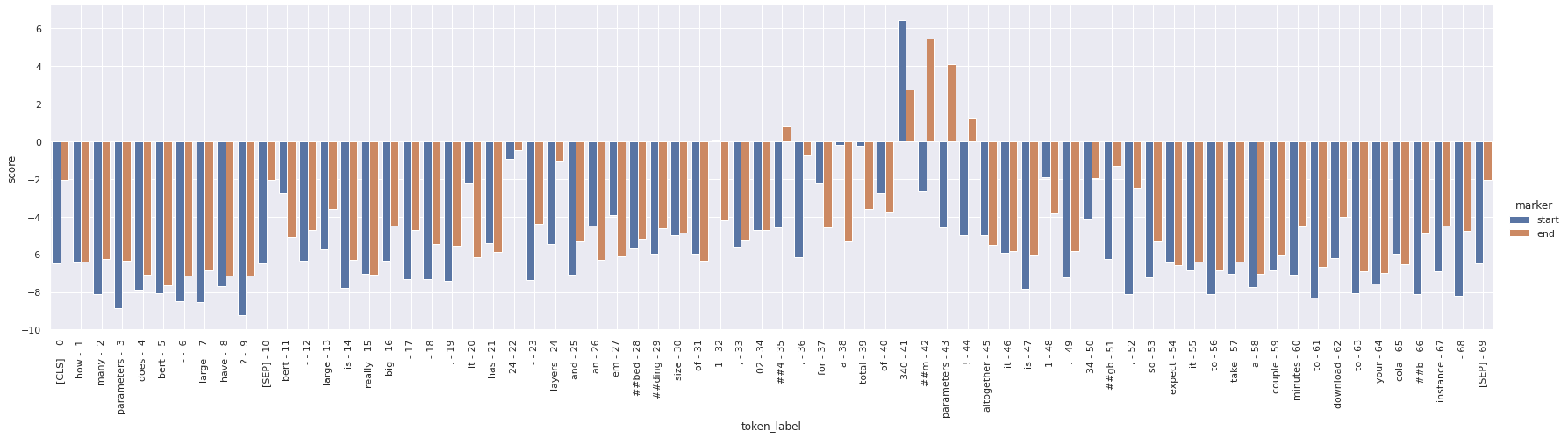
Alternate View
I also tried visualizing both the start and end scores on a single bar plot, but I think it may actually be more confusing then seeing them separately.
import pandas as pd
# Store the tokens and scores in a DataFrame.
# Each token will have two rows, one for its start score and one for its end
# score. The "marker" column will differentiate them. A little wacky, I know.
scores = []
for (i, token_label) in enumerate(token_labels):
# Add the token's start score as one row.
scores.append({'token_label': token_label,
'score': s_scores[i],
'marker': 'start'})
# Add the token's end score as another row.
scores.append({'token_label': token_label,
'score': e_scores[i],
'marker': 'end'})
df = pd.DataFrame(scores)
# Draw a grouped barplot to show start and end scores for each word.
# The "hue" parameter is where we tell it which datapoints belong to which
# of the two series.
g = sns.catplot(x="token_label", y="score", hue="marker", data=df,
kind="bar", height=6, aspect=4)
# Turn the xlabels vertical.
g.set_xticklabels(g.ax.get_xticklabels(), rotation=90, ha="center")
# Turn on the vertical grid to help align words to scores.
g.ax.grid(True)
5. More Examples
Turn the QA process into a function so we can easily try out other examples.
def answer_question(question, answer_text):
'''
Takes a `question` string and an `answer_text` string (which contains the
answer), and identifies the words within the `answer_text` that are the
answer. Prints them out.
'''
# ======== Tokenize ========
# Apply the tokenizer to the input text, treating them as a text-pair.
input_ids = tokenizer.encode(question, answer_text)
# Report how long the input sequence is.
print('Query has {:,} tokens.\n'.format(len(input_ids)))
# ======== Set Segment IDs ========
# Search the input_ids for the first instance of the `[SEP]` token.
sep_index = input_ids.index(tokenizer.sep_token_id)
# The number of segment A tokens includes the [SEP] token istelf.
num_seg_a = sep_index + 1
# The remainder are segment B.
num_seg_b = len(input_ids) - num_seg_a
# Construct the list of 0s and 1s.
segment_ids = [0]*num_seg_a + [1]*num_seg_b
# There should be a segment_id for every input token.
assert len(segment_ids) == len(input_ids)
# ======== Evaluate ========
# Run our example question through the model.
start_scores, end_scores = model(torch.tensor([input_ids]), # The tokens representing our input text.
token_type_ids=torch.tensor([segment_ids])) # The segment IDs to differentiate question from answer_text
# ======== Reconstruct Answer ========
# Find the tokens with the highest `start` and `end` scores.
answer_start = torch.argmax(start_scores)
answer_end = torch.argmax(end_scores)
# Get the string versions of the input tokens.
tokens = tokenizer.convert_ids_to_tokens(input_ids)
# Start with the first token.
answer = tokens[answer_start]
# Select the remaining answer tokens and join them with whitespace.
for i in range(answer_start + 1, answer_end + 1):
# If it's a subword token, then recombine it with the previous token.
if tokens[i][0:2] == '##':
answer += tokens[i][2:]
# Otherwise, add a space then the token.
else:
answer += ' ' + tokens[i]
print('Answer: "' + answer + '"')
As our reference text, I've taken the Abstract of the BERT paper.
import textwrap
# Wrap text to 80 characters.
wrapper = textwrap.TextWrapper(width=80)
bert_abstract = "We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models (Peters et al., 2018a; Radford et al., 2018), BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications. BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement)."
print(wrapper.fill(bert_abstract))
We introduce a new language representation model called BERT, which stands for
Bidirectional Encoder Representations from Transformers. Unlike recent language
representation models (Peters et al., 2018a; Radford et al., 2018), BERT is
designed to pretrain deep bidirectional representations from unlabeled text by
jointly conditioning on both left and right context in all layers. As a result,
the pre-trained BERT model can be finetuned with just one additional output
layer to create state-of-the-art models for a wide range of tasks, such as
question answering and language inference, without substantial taskspecific
architecture modifications. BERT is conceptually simple and empirically
powerful. It obtains new state-of-the-art results on eleven natural language
processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute
improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1
question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD
v2.0 Test F1 to 83.1 (5.1 point absolute improvement).
Ask BERT what its name stands for (the answer is in the first sentence of the abstract).
question = "What does the 'B' in BERT stand for?"
answer_question(question, bert_abstract)
Query has 258 tokens.
Answer: "bidirectional encoder representations from transformers"
Ask BERT about example applications of itself :)
The answer to the question comes from this passage from the abstract:
"...BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications."
question = "What are some example applications of BERT?"
answer_question(question, bert_abstract)
Query has 255 tokens.
Answer: "question answering and language inference"