
The Illustrated Image Captioning using transformers
Introduction
Image captioning is the process of generating caption i.e. description from input image. It requires both Natural language processing as well as computer vision to generate the caption.
The popular benchmarking dataset which has images and its caption are:
- Common Objects in Context (COCO). A collection of more than 120 thousand images with descriptions.
- Flickr 8K: A collection of 8 thousand described images taken from flickr.com.
- Flickr 30K: A collection of 30 thousand described images taken from flickr.com.
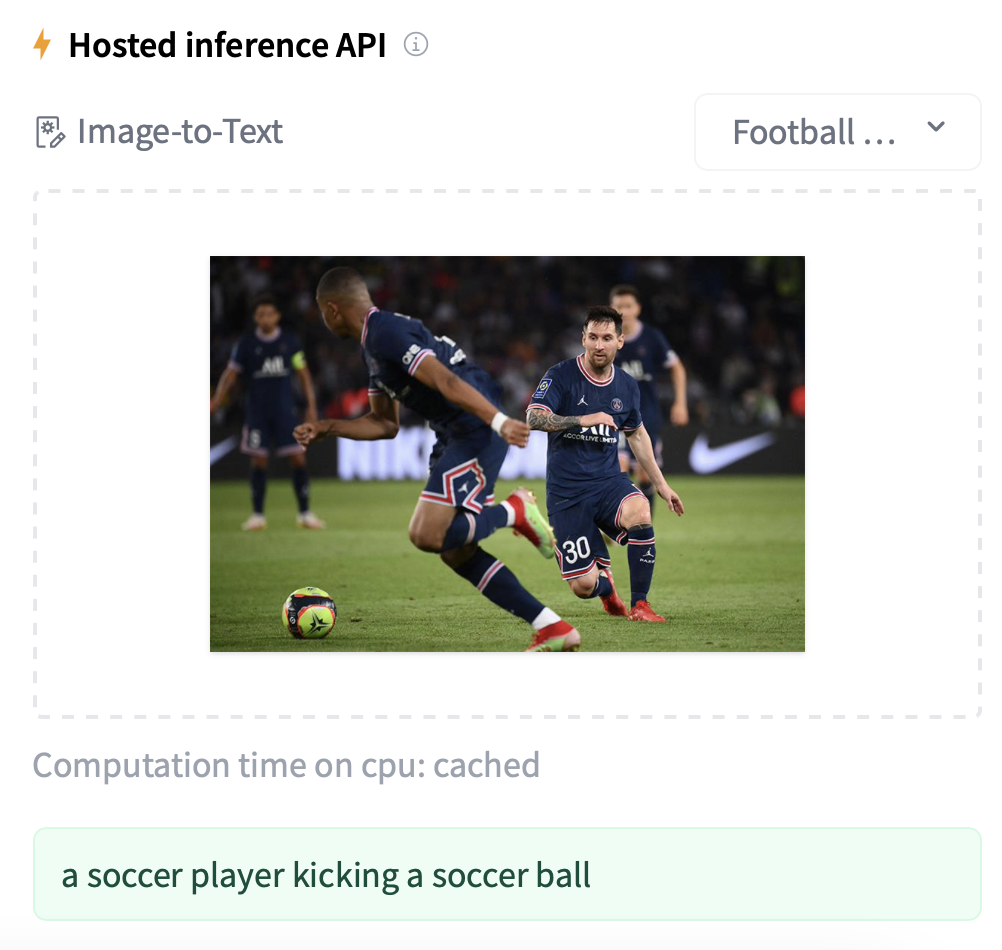
Try trained model: https://huggingface.co/nlpconnect/vit-gpt2-image-captioning
Vision Encoder Decoder Architecture

The Vision Encoder Decoder Model can be used to initialize an image-to-text model with any pre-trained Transformer-based vision model as the encoder (e.g. ViT, BEiT, DeiT, Swin) and any pre-trained language model as the decoder (e.g. RoBERTa, GPT2, BERT, DistilBERT).
Image captioning is an example, in which the encoder model is used to encode the image, after which an autoregressive language model i.e. the decoder model generates the caption.
import os
import datasets
from transformers import VisionEncoderDecoderModel, AutoFeatureExtractor,AutoTokenizer
os.environ["WANDB_DISABLED"] = "true"
import nltk
try:
nltk.data.find("tokenizers/punkt")
except (LookupError, OSError):
nltk.download("punkt", quiet=True)
Initialize VisionEncoderDecoderModel
from transformers import VisionEncoderDecoderModel, AutoTokenizer, AutoFeatureExtractor
image_encoder_model = "google/vit-base-patch16-224-in21k"
text_decode_model = "gpt2"
model = VisionEncoderDecoderModel.from_encoder_decoder_pretrained(
image_encoder_model, text_decode_model)
-
FeatureExtractoris used to extract features i.e. image patch resolution of 16x16. -
Tokenizeris used to tokenize and encode text features.
# image feature extractor
feature_extractor = AutoFeatureExtractor.from_pretrained(image_encoder_model)
# text tokenizer
tokenizer = AutoTokenizer.from_pretrained(text_decode_model)
# GPT2 only has bos/eos tokens but not decoder_start/pad tokens
tokenizer.pad_token = tokenizer.eos_token
# update the model config
model.config.eos_token_id = tokenizer.eos_token_id
model.config.decoder_start_token_id = tokenizer.bos_token_id
model.config.pad_token_id = tokenizer.pad_token_id
output_dir = "vit-gpt-model"
model.save_pretrained(output_dir)
feature_extractor.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
('vit-gpt-model/tokenizer_config.json',
'vit-gpt-model/special_tokens_map.json',
'vit-gpt-model/vocab.json',
'vit-gpt-model/merges.txt',
'vit-gpt-model/added_tokens.json',
'vit-gpt-model/tokenizer.json')
Data Loading and Preparation
We are going to use sample dataset from ydshieh/coco_dataset_script.
For using Full COCO dataset (2017), you need to download it manually first:
wget http://images.cocodataset.org/zips/train2017.zip
wget http://images.cocodataset.org/zips/val2017.zip
wget http://images.cocodataset.org/zips/test2017.zip
wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
wget http://images.cocodataset.org/annotations/image_info_test2017.zip Then to load the dataset:
COCO_DIR = ...(path to the downloaded dataset directory)...
ds = datasets.load_dataset("ydshieh/coco_dataset_script", "2017", data_dir=COCO_DIR)
import datasets
ds = datasets.load_dataset("ydshieh/coco_dataset_script", "2017", data_dir="./dummy_data/")
ds
DatasetDict({
train: Dataset({
features: ['image_id', 'caption_id', 'caption', 'height', 'width', 'file_name', 'coco_url', 'image_path'],
num_rows: 80
})
validation: Dataset({
features: ['image_id', 'caption_id', 'caption', 'height', 'width', 'file_name', 'coco_url', 'image_path'],
num_rows: 80
})
test: Dataset({
features: ['image_id', 'caption_id', 'caption', 'height', 'width', 'file_name', 'coco_url', 'image_path'],
num_rows: 16
})
})
# print single example
ds['train'][0]
{'image_id': 74,
'caption_id': 145996,
'caption': 'A picture of a dog laying on the ground.',
'height': 426,
'width': 640,
'file_name': '000000000074.jpg',
'coco_url': 'http://images.cocodataset.org/train2017/000000000074.jpg',
'image_path': '/.cache/huggingface/datasets/downloads/extracted/f1122be5b6fbdb4a45c67365345f5639d2e11a25094285db1348c3872189a0f6/train2017/000000000074.jpg'}
from PIL import Image
# text preprocessing step
def tokenization_fn(captions, max_target_length):
"""Run tokenization on captions."""
labels = tokenizer(captions,
padding="max_length",
max_length=max_target_length).input_ids
return labels
# image preprocessing step
def feature_extraction_fn(image_paths, check_image=True):
"""
Run feature extraction on images
If `check_image` is `True`, the examples that fails during `Image.open()` will be caught and discarded.
Otherwise, an exception will be thrown.
"""
model_inputs = {}
if check_image:
images = []
to_keep = []
for image_file in image_paths:
try:
img = Image.open(image_file)
images.append(img)
to_keep.append(True)
except Exception:
to_keep.append(False)
else:
images = [Image.open(image_file) for image_file in image_paths]
encoder_inputs = feature_extractor(images=images, return_tensors="np")
return encoder_inputs.pixel_values
def preprocess_fn(examples, max_target_length, check_image = True):
"""Run tokenization + image feature extraction"""
image_paths = examples['image_path']
captions = examples['caption']
model_inputs = {}
# This contains image path column
model_inputs['labels'] = tokenization_fn(captions, max_target_length)
model_inputs['pixel_values'] = feature_extraction_fn(image_paths, check_image=check_image)
return model_inputs
processed_dataset = ds.map(
function=preprocess_fn,
batched=True,
fn_kwargs={"max_target_length": 128},
remove_columns=ds['train'].column_names
)
processed_dataset
DatasetDict({
train: Dataset({
features: ['labels', 'pixel_values'],
num_rows: 80
})
validation: Dataset({
features: ['labels', 'pixel_values'],
num_rows: 80
})
test: Dataset({
features: ['labels', 'pixel_values'],
num_rows: 16
})
})
Define seq2seq training arguments
from transformers import Seq2SeqTrainer, Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
predict_with_generate=True,
evaluation_strategy="epoch",
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
output_dir="./image-captioning-output",
)
Using the `WANDB_DISABLED` environment variable is deprecated and will be removed in v5. Use the --report_to flag to control the integrations used for logging result (for instance --report_to none).
Define metric
import evaluate
metric = evaluate.load("rouge")
import numpy as np
ignore_pad_token_for_loss = True
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [label.strip() for label in labels]
# rougeLSum expects newline after each sentence
preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
return preds, labels
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
if ignore_pad_token_for_loss:
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds,
decoded_labels)
result = metric.compute(predictions=decoded_preds,
references=decoded_labels,
use_stemmer=True)
result = {k: round(v * 100, 4) for k, v in result.items()}
prediction_lens = [
np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds
]
result["gen_len"] = np.mean(prediction_lens)
return result
Training
from transformers import default_data_collator
# instantiate trainer
trainer = Seq2SeqTrainer(
model=model,
tokenizer=feature_extractor,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=processed_dataset['train'],
eval_dataset=processed_dataset['validation'],
data_collator=default_data_collator,
)
trainer.train()
***** Running training *****
Num examples = 80
Num Epochs = 3
Instantaneous batch size per device = 4
Total train batch size (w. parallel, distributed & accumulation) = 4
Gradient Accumulation steps = 1
Total optimization steps = 60
| Epoch | Training Loss | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|---|---|---|---|---|---|---|---|
| 1 | No log | 0.341840 | 18.242900 | 0.548200 | 18.205800 | 18.229100 | 7.000000 |
| 2 | No log | 0.333408 | 17.483000 | 2.052800 | 16.658800 | 16.677000 | 15.750000 |
| 3 | No log | 0.333202 | 19.999400 | 3.316300 | 18.790000 | 18.768300 | 13.500000 |
***** Running Evaluation *****
Num examples = 80
Batch size = 4
***** Running Evaluation *****
Num examples = 80
Batch size = 4
***** Running Evaluation *****
Num examples = 80
Batch size = 4
Training completed. Do not forget to share your model on huggingface.co/models =)
TrainOutput(global_step=60, training_loss=0.6188589096069336, metrics={'train_runtime': 344.1556, 'train_samples_per_second': 0.697, 'train_steps_per_second': 0.174, 'total_flos': 4.331133386883072e+16, 'train_loss': 0.6188589096069336, 'epoch': 3.0})
trainer.save_model("./image-captioning-output")
Saving model checkpoint to ./image-captioning-output
Configuration saved in ./image-captioning-output/config.json
Model weights saved in ./image-captioning-output/pytorch_model.bin
Feature extractor saved in ./image-captioning-output/preprocessor_config.json
tokenizer.save_pretrained("./image-captioning-output")
tokenizer config file saved in ./image-captioning-output/tokenizer_config.json
Special tokens file saved in ./image-captioning-output/special_tokens_map.json
('./image-captioning-output/tokenizer_config.json',
'./image-captioning-output/special_tokens_map.json',
'./image-captioning-output/vocab.json',
'./image-captioning-output/merges.txt',
'./image-captioning-output/added_tokens.json',
'./image-captioning-output/tokenizer.json')
Inference
from transformers import pipeline
# full dataset trained model can be found at https://huggingface.co/nlpconnect/vit-gpt2-image-captioning
image_captioner = pipeline("image-to-text", model="./image-captioning-output")
loading configuration file ./image-captioning-output/config.json
Model config VisionEncoderDecoderConfig {
"_commit_hash": null,
"_name_or_path": "./image-captioning-output",
"architectures": [
"VisionEncoderDecoderModel"
],
"decoder": {
"_name_or_path": "gpt2",
"activation_function": "gelu_new",
"add_cross_attention": true,
"architectures": [
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"bad_words_ids": null,
"begin_suppress_tokens": null,
"bos_token_id": 50256,
"chunk_size_feed_forward": 0,
"cross_attention_hidden_size": null,
"decoder_start_token_id": null,
"diversity_penalty": 0.0,
"do_sample": false,
"early_stopping": false,
"embd_pdrop": 0.1,
"encoder_no_repeat_ngram_size": 0,
"eos_token_id": 50256,
"exponential_decay_length_penalty": null,
"finetuning_task": null,
"forced_bos_token_id": null,
"forced_eos_token_id": null,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"is_decoder": true,
"is_encoder_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layer_norm_epsilon": 1e-05,
"length_penalty": 1.0,
"max_length": 20,
"min_length": 0,
"model_type": "gpt2",
"n_ctx": 1024,
"n_embd": 768,
"n_head": 12,
"n_inner": null,
"n_layer": 12,
"n_positions": 1024,
"no_repeat_ngram_size": 0,
"num_beam_groups": 1,
"num_beams": 1,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_scores": false,
"pad_token_id": null,
"prefix": null,
"problem_type": null,
"pruned_heads": {},
"remove_invalid_values": false,
"reorder_and_upcast_attn": false,
"repetition_penalty": 1.0,
"resid_pdrop": 0.1,
"return_dict": true,
"return_dict_in_generate": false,
"scale_attn_by_inverse_layer_idx": false,
"scale_attn_weights": true,
"sep_token_id": null,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"suppress_tokens": null,
"task_specific_params": {
"text-generation": {
"do_sample": true,
"max_length": 50
}
},
"temperature": 1.0,
"tf_legacy_loss": false,
"tie_encoder_decoder": false,
"tie_word_embeddings": true,
"tokenizer_class": null,
"top_k": 50,
"top_p": 1.0,
"torch_dtype": null,
"torchscript": false,
"transformers_version": "4.23.1",
"typical_p": 1.0,
"use_bfloat16": false,
"use_cache": true,
"vocab_size": 50257
},
"decoder_start_token_id": 50256,
"encoder": {
"_name_or_path": "google/vit-base-patch16-224-in21k",
"add_cross_attention": false,
"architectures": [
"ViTModel"
],
"attention_probs_dropout_prob": 0.0,
"bad_words_ids": null,
"begin_suppress_tokens": null,
"bos_token_id": null,
"chunk_size_feed_forward": 0,
"cross_attention_hidden_size": null,
"decoder_start_token_id": null,
"diversity_penalty": 0.0,
"do_sample": false,
"early_stopping": false,
"encoder_no_repeat_ngram_size": 0,
"encoder_stride": 16,
"eos_token_id": null,
"exponential_decay_length_penalty": null,
"finetuning_task": null,
"forced_bos_token_id": null,
"forced_eos_token_id": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.0,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"image_size": 224,
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": false,
"is_encoder_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layer_norm_eps": 1e-12,
"length_penalty": 1.0,
"max_length": 20,
"min_length": 0,
"model_type": "vit",
"no_repeat_ngram_size": 0,
"num_attention_heads": 12,
"num_beam_groups": 1,
"num_beams": 1,
"num_channels": 3,
"num_hidden_layers": 12,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_scores": false,
"pad_token_id": null,
"patch_size": 16,
"prefix": null,
"problem_type": null,
"pruned_heads": {},
"qkv_bias": true,
"remove_invalid_values": false,
"repetition_penalty": 1.0,
"return_dict": true,
"return_dict_in_generate": false,
"sep_token_id": null,
"suppress_tokens": null,
"task_specific_params": null,
"temperature": 1.0,
"tf_legacy_loss": false,
"tie_encoder_decoder": false,
"tie_word_embeddings": true,
"tokenizer_class": null,
"top_k": 50,
"top_p": 1.0,
"torch_dtype": null,
"torchscript": false,
"transformers_version": "4.23.1",
"typical_p": 1.0,
"use_bfloat16": false
},
"eos_token_id": 50256,
"is_encoder_decoder": true,
"model_type": "vision-encoder-decoder",
"pad_token_id": 50256,
"tie_word_embeddings": false,
"torch_dtype": "float32",
"transformers_version": null
}
loading weights file ./image-captioning-output/pytorch_model.bin
All model checkpoint weights were used when initializing VisionEncoderDecoderModel.
image_captioner("sample_image.png")
References
- https://huggingface.co/docs/transformers/model_doc/vision-encoder-decoder
- https://huggingface.co/docs/transformers/model_doc/encoder-decoder
- https://towardsdatascience.com/image-captioning-in-deep-learning-9cd23fb4d8d2
- https://huggingface.co/nlpconnect/vit-gpt2-image-captioning
Cited as
@article{kumar2022imagecaptioning,
title = "The Illustrated Image Captioning using transformers",
author = "Kumar, Ankur",
journal = "ankur3107.github.io",
year = "2022",
url = "https://ankur3107.github.io/blogs/the-illustrated-image-captioning-using-transformers/"
}
Comments