
Intro to Tokenization: A blog post written using OpenAI ChatGPT
OpenAI ChatGPT
ChatGPT, a new chatbot developed by OpenAI Inc. In this blog, I had tried to use the knowledge of bot to understand tokenization in NLP. I asked several questions related to tokenization i.e. what is tokenization, why it is hard, what are the type of tokenization etc. and below are the answers given by bot.
Natural Language Processing

Question to ChatGPT > What is natural language processing?
Natural language processing (NLP) is a field of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language. NLP algorithms use techniques from computer science, linguistics, and psychology to analyze and understand natural language, and to enable computers to communicate with humans in a way that is natural and intuitive. NLP techniques are used in a wide range of applications, including language translation, sentiment analysis, summarization, and text generation. These techniques are critical for enabling computers to process and understand the vast amounts of natural language data that is generated and shared every day.
Introduction to Tokenization
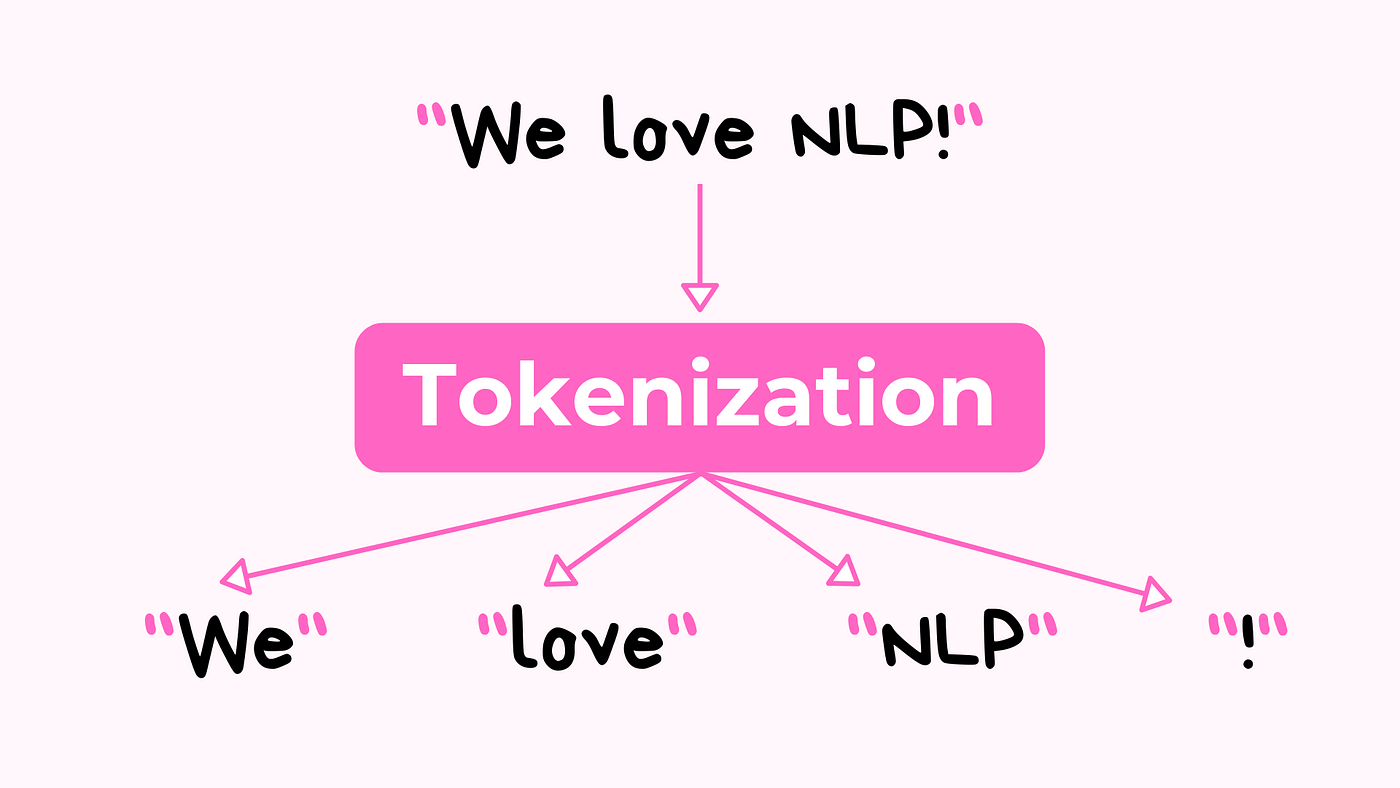
Question to ChatGPT > What is tokenization?
Tokenization is the process of breaking up a sequence of strings into smaller pieces called tokens. These tokens can be individual words, phrases, or subwords, depending on the specific algorithm being used. Tokenization is a critical step in natural language processing (NLP) because it allows the input text to be represented in a way that is more manageable and easier to process. By breaking the text up into smaller, discrete units, NLP algorithms can more easily analyze and understand the underlying structure and meaning of the text. Tokenization is often used in combination with other NLP techniques, such as word embedding and part-of-speech tagging, to improve the performance of natural language processing models.
Need of Tokenization in NLP
Question to ChatGPT > Why do we need tokenization?
Tokenization is an important step in natural language processing (NLP) because it allows the input text to be represented in a way that is more manageable and easier to process. By breaking the text up into smaller, discrete units called tokens, NLP algorithms can more easily analyze and understand the underlying structure and meaning of the text. This is especially important for tasks such as language translation, sentiment analysis, and text generation, where the input text may be long and complex, and the NLP model needs to be able to accurately capture the meaning and structure of the text. Additionally, tokenization allows NLP algorithms to better handle out-of-vocabulary words, and to capture the meaning of words in context. Overall, tokenization is a crucial step in natural language processing, and it is necessary for enabling computers to understand and generate human language.
Why Tokenization is Hard

Question to ChatGPT > Why tokenization is hard?
Tokenization can be a challenging task in natural language processing (NLP) because of the complexity and variability of human language. There are many different ways that words and phrases can be written, and the same word can have multiple meanings depending on the context in which it is used. This can make it difficult for NLP algorithms to accurately identify the boundaries between words and phrases, and to accurately capture the meaning of the text. Additionally, some languages, such as Chinese and Japanese, do not use explicit word boundaries, which can make tokenization even more challenging. Overall, while tokenization is a crucial step in NLP, it can be difficult to implement accurately and effectively due to the complexity and variability of human language.
Regex based Tokenization
Question to ChatGPT > Can we use regex for tokenization?
Regular expressions (regex) can be used for tokenization in natural language processing (NLP). Regex is a powerful tool for matching and extracting patterns from text, and it can be used to identify and split words and phrases in a given input. Regex can be especially useful for tokenization because it allows for flexibility and customization, and it can handle many of the complexities and variations of human language. However, regex is not always the best choice for tokenization, as it can be difficult to write and maintain complex regex patterns, and it may not be as efficient or effective as other tokenization techniques. Additionally, regex may not be able to handle some of the more challenging aspects of human language, such as context-dependent meaning and out-of-vocabulary words. Overall, while regex can be used for tokenization in NLP, it is important to carefully consider its strengths and limitations, and to choose the appropriate tokenization technique for the specific task at hand.
Advantages & Disadvantages of Regex Tokenization
Question to ChatGPT > What are the advantages and disadvantages of regex tokenization?
Regular expressions (regex) can be used for tokenization in natural language processing (NLP), and it has both advantages and disadvantages. Some advantages of using regex for tokenization include:
- Flexibility: Regex allows for a high degree of flexibility and customization, and it can be tailored to match specific patterns and boundaries in the input text. This can be useful for handling the complexities and variations of human language.
- Power: Regex is a powerful tool for matching and extracting patterns from text, and it can be used to identify and split words and phrases in a wide range of languages and contexts.
- Ease of use: Regex is a well-established and widely-used tool, and there are many resources and libraries available to help users write and test regex patterns.
However, there are also some disadvantages to using regex for tokenization, including:
- Difficulty: Writing and maintaining complex regex patterns can be difficult, and it may require a high level of expertise and experience.
- Inefficiency: Regex can be less efficient and slower than other tokenization techniques, especially for large and complex inputs.
- Limited capabilities: Regex may not be able to handle some of the more challenging aspects of human language, such as context-dependent meaning and out-of-vocabulary words.
Overall, while regex can be a useful tool for tokenization in NLP, it is important to carefully consider its strengths and limitations, and to choose the appropriate tokenization technique for the specific task at hand.
Kinds of Tokenization
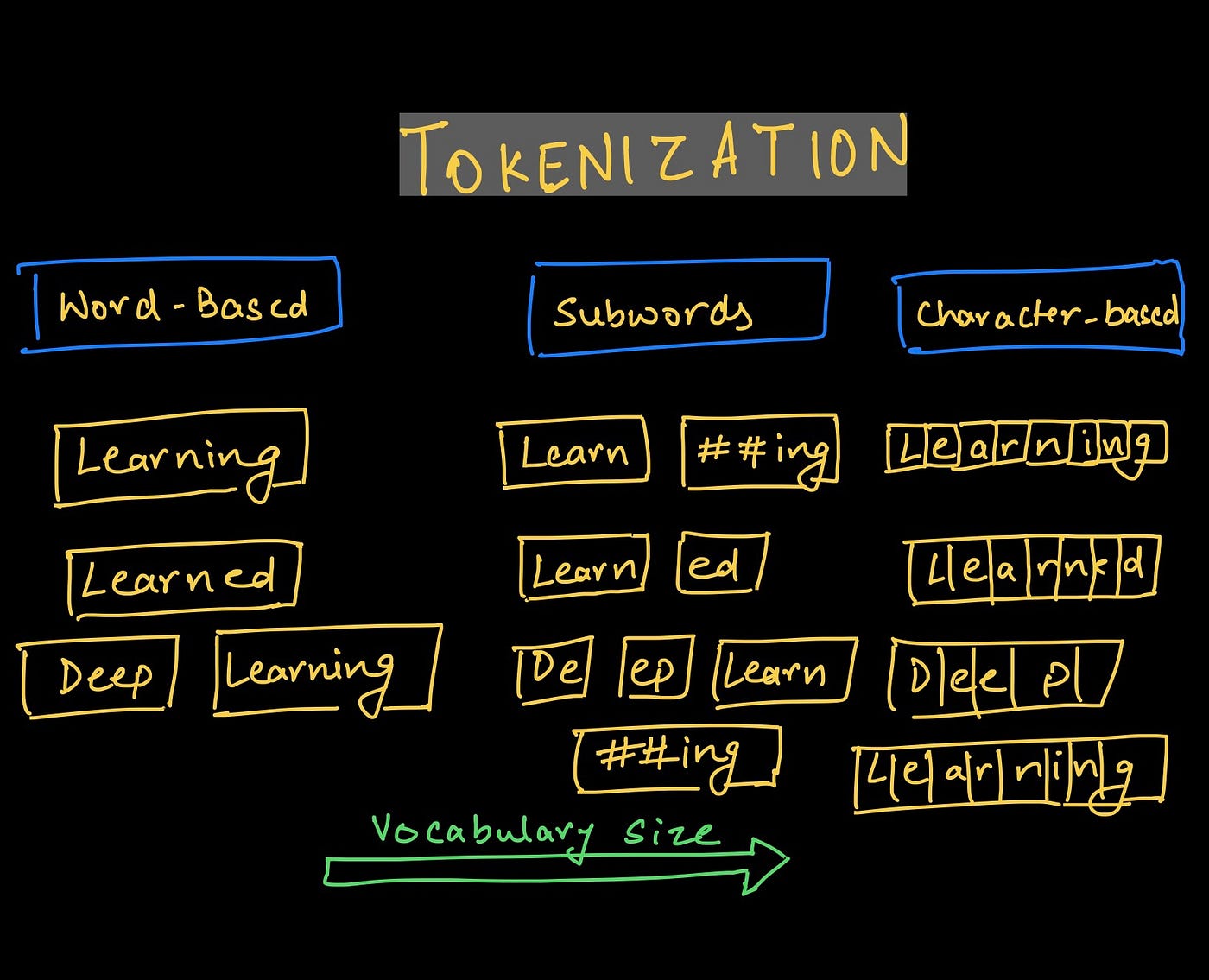
Question to ChatGPT > What are the kinds of tokenization used in NLP?
There are several different approaches to tokenization in natural language processing (NLP), each with its own advantages and disadvantages. Some common types of tokenization include:
-
Word tokenization: This is the most common form of tokenization, and it involves splitting the input text into individual words or tokens. This is often done by using white space or punctuation to identify word boundaries, but more advanced techniques, such as part-of-speech tagging and named entity recognition, can also be used. Word tokenization is simple and effective, but it may not be able to handle some of the more challenging aspects of human language, such as compound words and idiomatic expressions.
-
Sentence tokenization: This involves splitting the input text into individual sentences or clauses, rather than individual words. Sentence tokenization is useful for tasks such as summarization and text generation, where the input text may be long and complex, and it is important to identify the boundaries between sentences. Sentence tokenization can be more challenging than word tokenization, as it requires the algorithm to accurately identify the structure and meaning of the input text.
-
Subword tokenization: This involves breaking up words into smaller units called subwords or tokens. These subwords can be individual letters, syllables, or other units of meaning, depending on the specific algorithm being used. Subword tokenization is useful for handling out-of-vocabulary words and for capturing the meaning of words in context. Some common subword tokenization algorithms include Byte-Pair Encoding (BPE) and the WordPiece model.
Overall, there are many different approaches to tokenization in NLP, and the appropriate tokenization technique will depend on the specific task and the characteristics of the input text.
Subword Tokenization

Question to ChatGPT > Explain Subword tokenization with a simple example?
Subword tokenization is a technique used in natural language processing (NLP) to break up words into smaller units called subwords or tokens. These tokens can be individual letters, syllables, or other units of meaning, depending on the specific algorithm being used. Subword tokenization is useful for handling out-of-vocabulary words and for capturing the meaning of words in context.
For example, consider the word “understand”. This word can be tokenized using subword tokenization as follows:
- Begin by defining the vocabulary size and the initial set of subwords that will be used. For this example, we will use a vocabulary size of 5 and an initial set of subwords that includes the letters “u”, “n”, “d”, “e”, and “r”.
- Next, iterate over the input word and count the frequency of each pair of letters. In this case, the most frequent pair of letters is “un”, which appears twice in the word “understand”.
- Replace the most frequent pair of letters, “un”, with a single, unused letter, “s”. This generates the subwords “us”, “derstand”, which can be used as tokens.
- Finally, use the generated subwords to tokenize the input word. This can be done by replacing the word “understand” with the subwords “us” and “derstand”, resulting in the following sequence of tokens: “us”, “derstand”.
This is a simple example of how subword tokenization can be used to tokenize a single word. In practice, subword tokenization is typically applied to longer sequences of text, such as sentences or paragraphs, to enable natural language processing algorithms to better handle out-of-vocabulary words and to capture the meaning of words in context.
Techniques of Subword Tokenization

Question to ChatGPT > Explain different techniques in Subword tokenization?
There are several different approaches to subword tokenization, each with its own advantages and disadvantages. Some common types of subword tokenization include:
-
Byte-Pair Encoding (BPE): This is a simple and effective subword tokenization algorithm that works by iteratively replacing the most frequent pair of bytes (or characters) in the input text with a single, unused byte. This process continues until a predefined vocabulary size is reached, at which point the remaining subwords are used as tokens. BPE is widely used because it is simple to implement and efficient to run.
-
Unigram Language Model: This is a subword tokenization algorithm that uses a unigram language model to generate subwords. A unigram language model estimates the probability of each individual word in a given corpus of text, and uses this information to generate subwords that are likely to appear in the text. This approach can be more effective than BPE at capturing the meaning of words in context, but it is also more computationally expensive.
-
WordPiece Model: This is a subword tokenization algorithm that is used in the BERT model. It is similar to BPE, but it uses a predefined vocabulary of subwords that are derived from a large corpus of text. This allows the model to make use of common subwords that are likely to appear in the input text, while still allowing for out-of-vocabulary words.
Byte-Pair Encoding
Question to ChatGPT > Implement a Byte-Pair Encoding in python?
To implement Byte-Pair Encoding (BPE) in Python, you can follow these steps:
- Begin by importing the necessary libraries and defining the input text that will be tokenized. You will need to import the
relibrary for regular expressions, and thecollectionslibrary for counting the frequency of pairs of bytes.
import re
import collections
text = "The quick brown fox jumped over the lazy dog."
- Next, define the vocabulary size and the initial set of subwords that will be used. The vocabulary size determines the maximum number of subwords that can be generated, and the initial set of subwords should be chosen based on the specific language or text that you are working with. For this example, we will use a vocabulary size of 10 and an initial set of subwords that includes the letters “T”, “h”, “e”, “q”, “u”, “i”, “c”, “k”, “b”, and “r”.
vocab_size = 10
subwords = ["T", "h", "e", "q", "u", "i", "c", "k", "b", "r"]
- Next, iterate over the input text and count the frequency of each pair of bytes (or characters) in the text. This can be done using a regular expression to match and extract pairs of bytes, and the
Counterclass from thecollectionslibrary to count the frequency of each pair.
References
- https://openai.com/blog/chatgpt/
- https://thinkpalm.com/blogs/natural-language-processing-nlp-artificial-intelligence/
- https://medium.com/@utkarsh.kant/tokenization-a-complete-guide-3f2dd56c0682
- https://towardsdatascience.com/the-evolution-of-tokenization-in-nlp-byte-pair-encoding-in-nlp-d7621b9c1186
- https://blog.floydhub.com/tokenization-nlp/
- https://www.thoughtvector.io/blog/subword-tokenization/
- https://blog.floydhub.com/tokenization-nlp/
- https://towardsdatascience.com/the-evolution-of-tokenization-in-nlp-byte-pair-encoding-in-nlp-d7621b9c1186
Comments